ニューラルネットワークの学習
ニューラルネットワークの学習は、次の一般的に方法で実行されます。
- 学習に使用されている画像セット内の各画像 (学習セット ダイアログで定義) が、指定された特徴のサイズを使用して全体でサンプリングされます。
- 結果のサンプルが、VisionPro Deep Learning ディープニューラルネットワークに入力として提供されます。
- ニューラルネットワークは、サンプルごとに特定の応答 (ツールの種類に応じて) を生成し、この応答が、学習画像内のサンプルの位置に関連付けられた画像のラベル付けと比較されます。
- サンプルが処理され、再処理されるにつれて、ネットワーク内部の重みが繰り返し調整されます。ネットワーク学習システムは、ネットワークの応答とユーザによって提供されたラベル付けの間の誤差 (差異または不一致) を低減することを目標にして、ネットワークの重みを絶えず調整します。
- すべての学習画像サンプルが、エポック数パラメータで指定された回数以上含まれるまで、このプロセス全体が何度も繰り返されます。
|
|
|
|
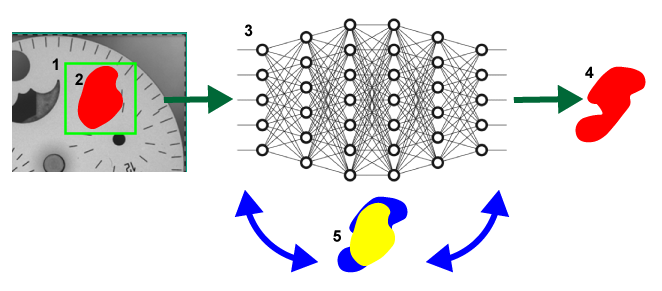
1 |
サンプリング領域。 |
|
2 |
ユーザが描画したラベル付き欠陥領域。 |
|
3 |
ニューラルネットワーク。 |
|
4 |
ネットワークによる応答。 |
|
5 |
ラベル付き欠陥 (黄) とネットワークの応答 (青) の間の不一致 (誤差) を低減するために重みを繰り返し調整するプロセス。 |
ニューラルネットワークの学習の特性は、学習させているツールの種類に応じて多少異なります。
-
位置決め (青) ツールのネットワークの学習
位置決め (青) ツールのネットワークには、画像内の特徴を見つけて識別することを学習させます。ユーザによる青のツールのラベル付けによって、画像内にあるすべての対象の特徴の位置と ID を識別します。画像内の特定のサンプリング領域の場合、ネットワークの学習目標は、サンプリング領域内にある特徴のポーズを正確に返すことです。サンプリング領域に特徴が含まれていない場合、ネットワークはそのサンプルに対する応答を生成しない必要があります。
位置決め (青) ツールのネットワークの学習目標は、画像のラベル付けによって定義された実際の特徴のポーズおよび ID と、検出されたポーズおよび ID の間の不一致を低減することです。
-
読み取り (青) ツールのネットワークの学習
読み取り (青) ツールは、位置決め (青) ツールと同様のアプローチを使用しますが、ポーズの不一致にはあまり注意が払われません。
-
解析 (赤) ツール (フォーカススーパーバイズドモード、高詳細モード) のネットワークの学習
解析 (赤) ツール (解析 (赤) スーパーバイズドと解析 (赤) 高詳細モード) のネットワークに、画像内の欠陥領域を見つけて識別することを学習させます。解析 (赤) ツールのスーパーバイズドモード/高詳細モードで行うラベル付けでは、ラベル付き画像内のすべての欠陥ピクセルにラベルを付けます。画像内の特定のサンプリング領域の場合、ネットワークの学習目標は、欠陥ピクセルを欠陥として正しく識別することです。サンプリング領域に欠陥ピクセルが含まれていない場合は、ネットワークが応答を生成しない必要があります。
解析 (赤) ツールのスーパーバイズドモード/高詳細モードのネットワーク学習目標は、欠陥のラベル付けと検出された欠陥の間の空間的不一致を低減することです。
-
解析 (赤) ツール (アンスーパーバイズドモード) のネットワークの学習
解析 (赤) ツール (アンスーパーバイズド) のネットワークには、画像内の欠陥領域を見つけることを学習させます。アンスーパーバイズドモードの解析 (赤) ツール用の学習画像セットは、欠陥のない既知の画像だけのコレクションです。学習の目標は、単純に、ネットワークが学習画像セットからのサンプルに対して応答を生成しないことです。
-
分類 (緑) ツールのネットワークの学習
分類 (緑) ツールは、Deep Learning ツールの中で唯一、入力画像全体に対して 1 つの結果を生成します。高詳細モードとフォーカスモードがあります。それでも他のツールと同じ方法で画像サンプルを収集しますが、サンプルは処理中にプールされ、画像全体に対して 1 つの結果が生成されます。
分類 (緑) ツールのネットワークの学習目標は、ラベル付きクラスと検出されたクラスの間の不一致の数を低減することです。
-
ネットワークの学習の制御
ネットワークの学習フェーズに影響を与える最大で唯一の決定要素は、学習画像セットの構成です。すべてのツールのデフォルトの動作では、ランダムに選択された画像とともに、画像セット内の画像の 50% を使用して学習します。