解析 (赤) ツール – 高詳細
解析 (赤) 高詳細 は 解析 (赤) スーパーバイズド と同じタスクを完了しますが、結果の提供方法にいくつかの違いがあります。つまり、解析 (赤) 高詳細 は 解析 (赤) スーパーバイズド と同様に、欠陥の外観をネットワークに学習させることを目的としています。
高詳細モードでは、フォーカスモードとは異なるアーキテクチャを使用します。アーキテクチャの違いにより、ビュー全体からサンプリングするため、[ツールのパラメータ] ペインにはサンプリングパラメータがありません。このため、高詳細モードではフォーカスモードより学習/処理に時間がかかりますが、ピクセルレベルで得られる結果は精度が高くより詳細です。高詳細モードの画像のラベル付け方法とモデルの作成方法はフォーカスモードと基本的に同じですが、ツールパラメータが一部異なります。
解析 (赤) スーパーバイズド と同様に、バイナリクラス (良好/不良) のみが 解析 (赤) 高詳細 でサポートされています。つまり、複数のクラスはサポートされていません。
解析 (赤) 高詳細 で画像を「良好」とラベル付けした場合 (つまり欠陥領域を含んでいない画像)、その画像が学習セットに追加されると、ツールではその画像を学習に使用します。特に、ツールはネットワークの学習を試みて、「良好」のラベルが付いた画像が欠陥の応答を生成しないようにします。ラベル付きの、欠陥のない「良好」な画像を学習画像セットに追加すると、良好な画像と不良画像を分類するツールのパフォーマンスを検証するのに役立ちます。
高詳細モードの学習プロセスは次のとおりです。
-
遭遇することが予想されるあらゆる欠陥を網羅した画像を収集します。
-
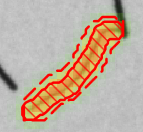
学習画像セット内の各画像を確認し、慎重に欠陥にラベルを付けます。より良好なモデルを作成するには、領域を描画することが重要です。
欠陥 ラベル 
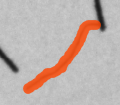
-
いくつかの良好な画像を追加して、「良好」としてラベルを付けます。
-
ツールパラメータを編集します。
-
ツールを学習させ、結果を確認します。
-
欠陥を含んでいる、学習中に使用されなかった画像と、欠陥を含んでいない良好な画像を提示することで、ツールを検証します。
欠陥のマーキング