OCRMax
La fonction OCRMax lit et/ou vérifie une chaîne de texte au sein d’une région d’intérêt (ROI), après avoir appris des polices de caractère définies par l’utilisateur. OCRMax effectue une reconnaissance optique des caractères (OCR) par le biais d’un processus de segmentation et de classification. La segmentation survient en premier, utilisant des techniques de seuillage pour identifier les zones de l’image semblant contenir des lignes de texte. Une fois le texte segmenté en caractères, les caractères sont appris et stockés sous forme de base de données. La classification survient pendant l’exécution, assurant la lecture de tout texte trouvé après exécution de la segmentation. Pour cela, les images des caractères segmentés sont comparées aux caractères appris dans la police.
Pendant le processus de segmentation, la fonction OCRMax détermine l’emplacement de la ligne de texte dans la ROI, et calcule l’angle, l’inclinaison et la polarité du texte. La région est ensuite normalisée pour supprimer les bruits indésirables avant d’être binarisée en pixels de premier plan et d’arrière-plan. Dans l’image binarisée, une analyse des blobs est effectuée pour produire des fragments de caractère. Chaque fragment de caractère représente un seul blob. Les fragments de caractère sont ensuite regroupés pour former des caractères, qui se voient attribuer une région de caractère. La région du caractère est un cadre englobant strict et non modifiable, qui englobe tous les pixels de premier plan (c’est-à-dire d’encre) dans la ROI.
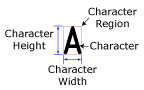
La ligne de texte dans la ROI est divisée en images des caractères individuels, et chaque caractère est inclus dans un rectangle de caractère non modifiable. La ROI définit l’emplacement approximatif, l’angle et l’inclinaison de la ligne de texte. Les paramètres Gamme d’écart angulaire et Plage d’inclinaison de l’onglet Segmentation peuvent être utilisés pour compenser les variations, si nécessaire.
OCRMax – entrées
La feuille de propriétés OCRMax propose un certain nombre de paramètres pour ajuster les résultats de la fonction. Elles sont accessibles dans les onglets de la feuille de propriétés : Général, Segmentation, Apprendre la police, Recherche ciblée, Résultats et Diagnostics.
De plus, le bouton Mise au point automatique de la feuille de propriétés OCRMax ouvre la Boîte de dialogue Mise au point automatique utilisée pour calculer automatiquement les paramètres optimaux de segmentation et entraîner une base de données de polices. Lorsqu’une ou plusieurs images sont chargées et que la boîte de dialogue Mise au point automatique est ouverte, chaque image est analysée pour s’assurer que les caractères sont correctement segmentés et classés. Si les caractères ne sont pas correctement segmentés, l’algorithme de Mise au point automatique de la fonction OCRMax calcule les paramètres optimaux de Segmentation pour l’image actuelle ainsi que pour les précédentes. Au fur et à mesure que des images sont utilisées pour l’apprentissage, l’algorithme de mise au point automatique de la fonction OCRMax devient plus fiable et plus précis. Une fois les résultats obtenus satisfaisants, la boîte de dialogue Mise au point automatique est fermée. Les nouveaux paramètres de segmentation sont appliqués et la base de données de polices est mise à jour avec les caractères appris.
- Un seul cycle est nécessaire, au lieu de deux : une fois pour mettre au point les paramètres de segmentation, et le second pour l’apprentissage.
- La précision de lecture doit être meilleure car les caractères sont entraînés automatiquement avec les paramètres de segmentation obtenus pendant le processus de mise au point.
OCRMax – Sorties
|
Renvoie |
Une structure de données OCRMax contenant la chaîne de caractères lue, ou #ERR si l’un des paramètres d’entrée est incorrect. |
||||||||||||||||||||||||||||||
|
Résultats |
Un tableau de résultats est créé dans la feuille de calcul, avec les Vision Data Access functions OCRMax suivantes, lorsqu’une fonction OCRMax est insérée dans une cellule pour la première fois.
|