OCRMax
La función OCRMax lee y/o verifica una cadena de texto en una región de interés (RDI) después de haber sido entrenada con fuentes de caracteres definidas por el usuario. La función OCRMax realiza un proceso de reconocimiento óptico de caracteres basado en operaciones de segmentación y clasificación. Realiza primero la segmentación y utiliza técnicas de umbral para identificar las áreas de la imagen que contienen líneas de texto. Una vez segmentado el texto en caracteres, éstos se entrenan y almacenan en una base de datos de fuentes. La clasificación se produce en tiempo de ejecución e implica «leer» los textos detectados tras la operación de segmentación. En particular, se comparan las imágenes de los caracteres segmentados con los caracteres entrenados de la fuente.
Durante el proceso de segmentación, la función OCRMax determina la ubicación de la línea de texto dentro de la RDI y calcula el ángulo, la inclinación del texto y la polaridad. A continuación, se normaliza la región para eliminar ruido molesto antes de binarizar la región de la imagen en píxeles primer plano y píxeles de fondo. En la imagen binarizada, se realiza un análisis de blobs para obtener fragmentos de caracteres, siendo cada fragmento de carácter un blob individual. A continuación, se agrupan los fragmentos de caracteres para formar caracteres y a estos caracteres se les asigna una región de carácter. Una región de carácter es un cuadro delimitador, envolvente y no editable, que encierra ajustadamente todos los píxeles que hay en el primer plano (es decir, de tinta) de la RDI.
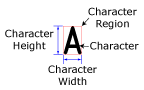
La línea de texto en la RDI se subdivide en imágenes de caracteres individuales y cada uno de estos caracteres está encerrado en un rectángulo envolvente de carácter no editable. La RDI define aproximadamente la ubicación, el ángulo y la inclinación de la línea de texto. Los parámetros «Intervalo de ángulos» e «Intervalo de inclinaciones» de la ficha Segmentación pueden utilizarse para compensar las variaciones, si fuera necesario.
OCRMax Entradas
La hoja de propiedades de OCRMax ofrece una serie de parámetros para ajustar los resultados de la función. Se puede acceder a estos parámetros por medio de las pestañas de la hoja de propiedades: General, Segmentación, Entrenar fuente, Fielding, Resultados y Diagnostics.
Además, el botón Auto-Tune en la hoja de propiedades de OCRMax inicia el Cuadro de diálogo Auto-Tune que se utiliza para calcular automáticamente los parámetros de segmentación óptimos y entrenar una base de datos de fuentes. Cuando se tienen una o varias imágenes cargadas y el cuadro de diálogo Auto-Tune en ejecución, cada imagen es sometida a un examen para verificar si se están segmentando y clasificando correctamente los caracteres. Si no se están segmentando correctamente los caracteres, el algoritmo de ajuste automático, Auto-Tune, de la función OCRMax calcula el valor óptimo de los parámetros de Segmentación a utilizar para segmentar la imagen actual y, también, para las imágenes entrenadas previamente. A medida que se entrenan más imágenes, el algoritmo Auto-Tune de la función OCRMax se vuelve cada vez más fiable y preciso. Una vez se obtienen resultados satisfactorios, se cierra el cuadro de diálogo Auto-Tune, se aplican los nuevos parámetros de segmentación y se actualiza la base de datos de fuentes con los caracteres recién entrenados.
- Sólo hay que pasar una vez por las imágenes, en lugar de tener que realizar dos pasadas (una para ajustar los parámetros de Segmentación y otra para entrenar).
- La precisión en la lectura debería haber mejorado porque los caracteres se entrenan automáticamente con los parámetros de segmentación obtenidos durante el proceso de ajuste.
OCRMax Salidas
|
Devuelve |
Una estructura de datos OCRMax que contiene la cadena de caracteres leída, o #ERR si alguno de los parámetros de entrada no es válido. |
||||||||||||||||||||||||||||||
|
Resultados |
Cuando se inserta inicialmente la función OCRMax en una celda, se crea una tabla de resultados en la hoja de cálculo con las siguientes OCRMax Vision Data Access functions.
|