결과 해석
도구 학습과 프로세싱이 끝나면, 도구 결과는 모든 뷰에서 계산됩니다. 하지만, 도구를 정확하게 평가하려면 반드시 테스트 세트에서 계산된 결과만을 검토해야 합니다.
테스트 세트: 결과 평가를 위한 이미지들
VisionPro Deep Learning의 통계적 지표들은 트레이닝된 신경망의 성과를 평가하는 데 이용됩니다. 딥러닝의 패러다임에서, 평가(evaluation)란 트레이닝이 끝난 신경망 모델을 테스트 데이터(라벨링이 되어 있지만 트레이닝에는 사용되지 않은 데이터)로 평가하는 일을 말합니다. 즉, 통계 지표들을 활용해 어떤 신경망 모델이 쓸만한 것인지 그리고 성능은 괜찮은지를 결정할 때, 이 통계 지표들은 반드시 테스트 데이터에서만 산출되어야 합니다.
신경망 모델 즉 도구(Blue 위치/읽기 또는 Green 분류 또는 Red 분석)를 트레이닝한 후에, 모델이 얼마나 잘 트레이닝되었는지 점검하려면 이 모델을 트레이닝하는 데 사용한 데이터로 모델을 테스트할 수 없음에 주의하십시오. 트레이닝 데이터는 이미 트레이닝된 모델을 평가하는 데 사용할 수 없습니다. 왜냐하면, 트레이닝 과정에서는 트레이닝 데이터가 주어졌을 때 가장 좋은 성능을 내야 하므로 모델은 이미 이 데이터에 맞춰졌기 때문입니다. 그래서 이 데이터는 생소한 그리고 이질적인 데이터가 주어졌을 때 모델이 얼마나 일반적으로 그리고 기대한대로 잘 작동하는지 알려줄 수 없습니다.
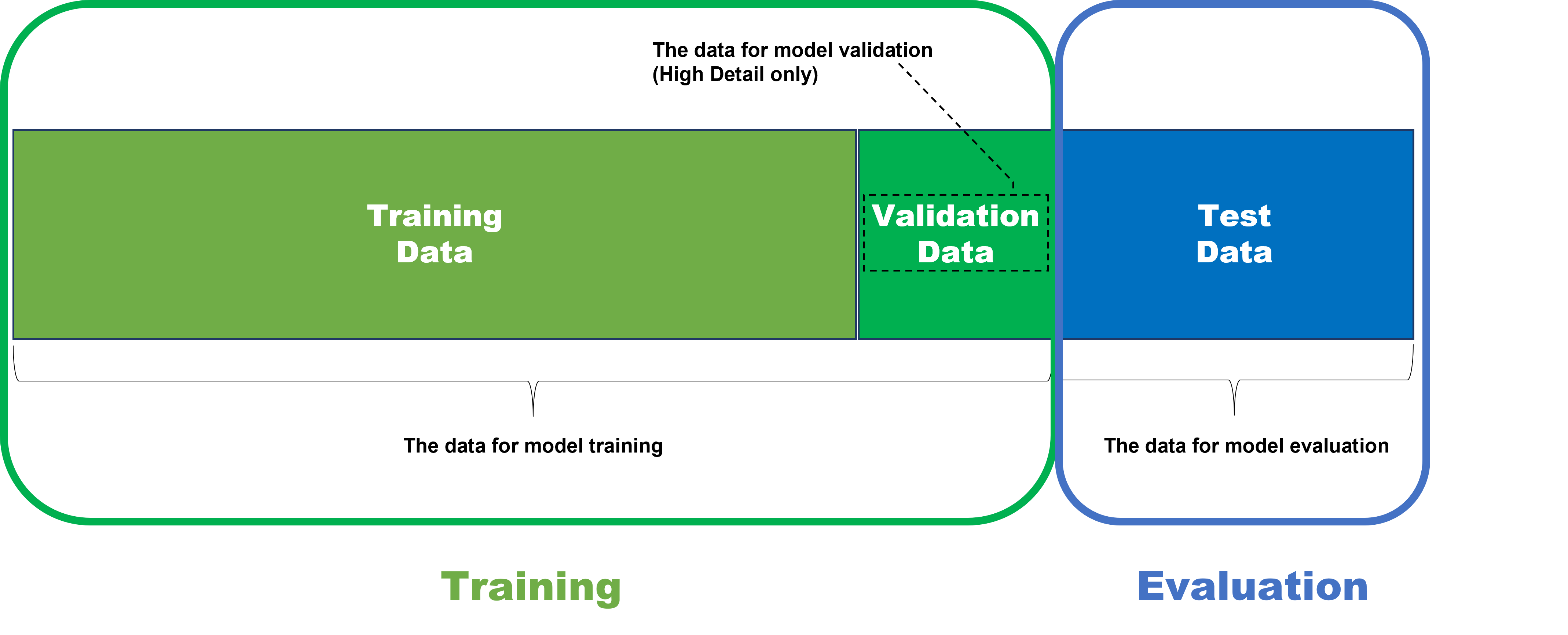
결국, 모델의 가용성과 성능을 공정하고 정확하게 테스트하려면, 모델은 트레이닝 과정을 포함하여 반드시 과거에 입력 받지 않은 데이터를 대상으로 테스트를 받아야 합니다. 이것이 바로 모델 평가를 위해 사용되는 데이터가 테스트 데이터 세트로 불리는 이유입니다.
테스트 데이터 세트는 트레이닝에 사용되지 않지만 검증(validation) 데이터 세트는 트레이닝에 사용됨에 유의하십시오. 검증 데이터는 트레이닝 세트에 속하며 그 목적은 트레이닝 데이터에서 생성된 많은 신경망 모델들 중에서 트레이닝 결과로 반환하기 위한 가장 좋은 모델을 선택하는 것입니다. High Detail 모드들은 트레이닝을 할 때 validation loss(validation 데이터에서 계산하는 loss)를 각 신경망 모델마다 계산하며, 그중에서 성능 그리고 가용성 측면에서 가장 좋은 loss를 보이는 모델을 최종적으로 트레이닝 결과로 선택합니다. 다시 강조하면, validation 데이터는 오직 Green 분류 High Detail 모드, Red 분석 High Detail 모드에서만 사용됩니다. 다른 모드 도구들은 validation 데이터를 사용하지 않으며 이들은 트레이닝 데이터에서 계산한 loss로 최적 모델을 선택합니다.
Database Overview(데이터베이스 개요)
데이터베이스 개요 창을 통해, 트레이닝에 이용된 이미지 및 뷰에 대한 정보와 Cognex Deep Learning 도구들이 생성한 통계량 결과를 볼 수 있습니다. 이 창은 선택된 도구에 따라 디스플레이가 다릅니다.
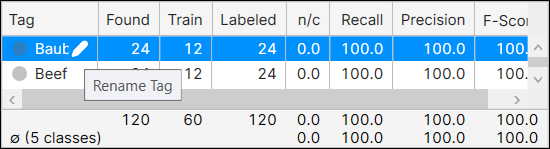
태그 이름을 클릭한 후 연필 아이콘을 클릭해 '태그 이름 변경' 대화 상자를 띄우면 태그 이름을 변경할 수 있습니다.
전문가 모드에서는, 필터 필드를 이용해 이미지/뷰를 분리하고 해당 이미지/뷰에 대해서만 통계 분석을 수행할 수 있습니다. 이미지/뷰의 필터링 systax에 대한 자세한 내용은 디스플레이 필터 및 필터 항목을 참조하고, 해당 필터의 자세한 사용 방법은 테스트 이미지 샘플 Set항목을 참조하십시오.
프로세싱 시간
개별 도구의 프로세싱 시간은 아래와 같이 데이터베이스 개요에 표시됩니다:
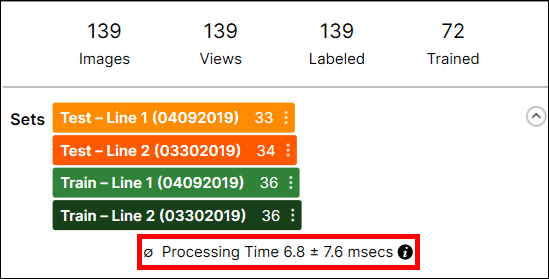
프로세싱 시간은 프로세싱 시간과 사후 프로세싱 시간이 더해진 시간입니다. 다수 도구를 포함하는 스트림의 프로세싱 시간은 VisionPro Deep Learning GUI에서 제공되지 않으며, 스트림 내에 있는 도구의 실행 시간을 합산하여 추정할 수 없습니다. 프로세싱 시간에는 도구 간에 뷰를 준비하고 전송하는 시간이 포함되기 때문입니다.
결과 지표
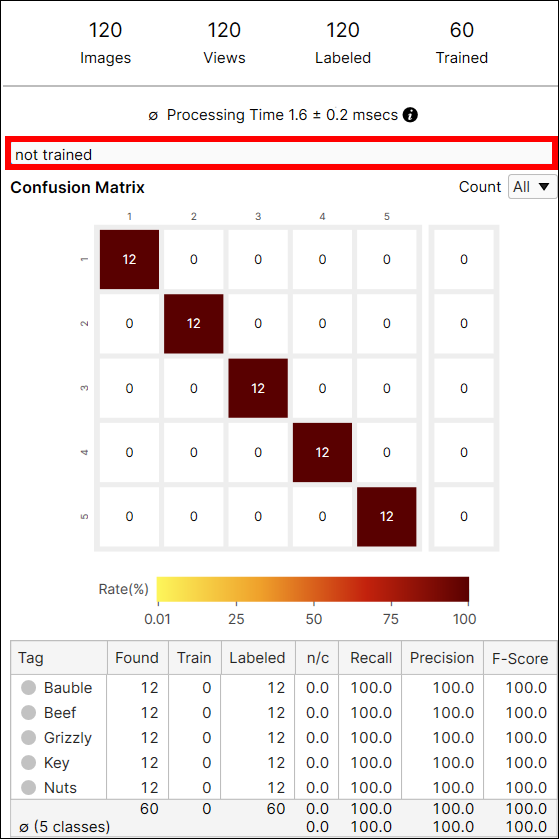
Green 분류 도구의 통계량에는 Recall, Precision, F-Score 값이 있습니다. 또한 상호작용이 가능한 Confusion Matrix(데이터베이스 개요에 표시됨)도 제공됩니다.
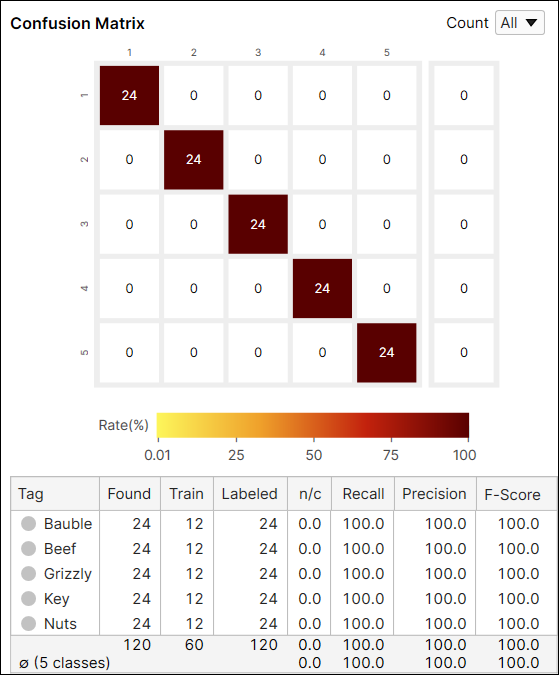
Green 분류 도구 High Detail 모드 지표 결과는 다음과 같습니다:
- Confusion Matrix
- Precision, Recall, F-Score
기본 개념: False Positives, False Negatives
통계적 결과 외에도, 이 결과에 따라 False Positive 및 False Negative 결과가 어떤 영향을 받는지도 이해해야 합니다.
이미지에서 결함을 찾아내는 이미지 검사 기계가 있다고 가정해보겠습니다. 이 기계가 어떤 이미지에서 결함을 찾아낸다면 이 이미지 검사 결과는 Positive라고 하고, 어떤 결함도 찾지 못하면 검사 결과를 Negative라고 합니다. 이 때, 검사 결과 통계치는 다음과 같이 요약될 수 있습니다:
-
False Positive (또는 제1종 오류)
-
이미지가 특정 클래스에 실제로는 속하지 않음에도 불구하고 이미지 검사기는 이 특정 클래스에 속한다고 판단함.
-
-
False Negative (또는 제2종 오류)
-
이미지가 특정 클래스에 실제로는 속함에도 불구하고 이미지 검사기는 이 특정 클래스에 속하지 않는다고 판단함.
-
기본 개념: Precision, Recall, F-Score
False Positives와 False Negatives는 모든 VisionPro Deep Learning 도구들에서 쓰이는 통계적 결과값들인 Precision과 Recall로 요약되어 표현됩니다.
- Precision
- 일반적으로, 낮은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)를정확하게 분류하는 데 실패하며, 따라서 많은 False Positive(제1종 오류)가 발생합니다.
- 일반적으로, 높은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터) 클래스를 정확하게 분류하는 데 성공하지만, 만약 Recall이 낮을 경우 많은 False Negative(제2종 오류)가 발생할 가능성이 있습니다.
- Recall
- 일반적으로, 낮은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터) 클래스를 충분히 분류하는 데 실패하며, 따라서 많은 False Negative(제2종 오류)가 발생합니다.
- 일반적으로, 높은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터) 클래스를 충분히 분류하는 데 성공하지만, 만약 Precision이 낮을 경우 많은 False Positive(제1종 오류)가 발생할 가능성이 있습니다.
요약하면,
- Precision - 라벨 지정된 클래스와 일치하는 클래스를 검출한 비율.
- Recall - 도구에 의해 정확하게 식별된, 라벨 지정된 클래스의 비율.
- F-Score – Recall과 Precision의 조화 평균.
거의 모든 검사 사례에서 (예외가 있을 수 있음) 이상적인 통계적 결과는 높은 Precision과 높은 Recall을 동시에 보이는 결과입니다.
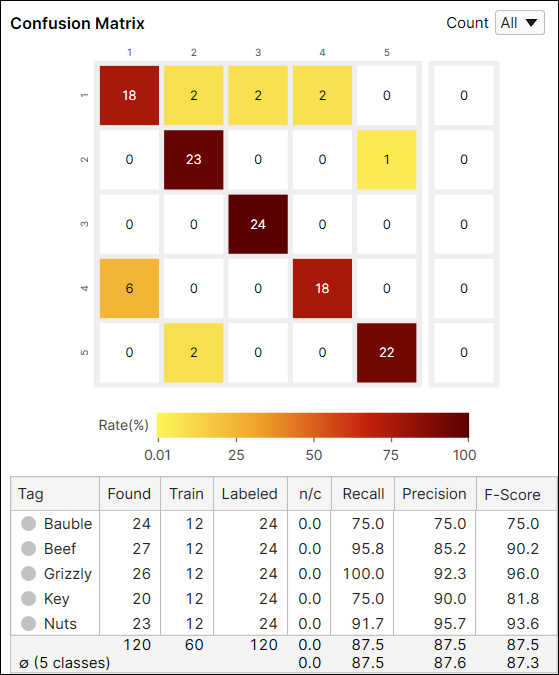
Green 분류 Confusion Matrix
Confusion Matrix는 ground truth와 도구의 예측을 시각적으로 표현한 것입니다. Green 분류 도구에서 제공하는 Confusion Matrix는 Recall 및 Precision 점수를 표로 나타낸 것입니다. 왼쪽에 있는 Confusion Matrix는 오른쪽에 있는 표를 표현한 것입니다. 데이터베이스 개요에서 Confusion Matrix에 있는 각 동그라미들을 클릭하면, 표에서 해당하는 칸에 있는 항목(뷰들)이 뷰 브라우저에 나타날 것입니다.
|
예측된 클래스 |
||||||
|
Bauble |
Beef |
Grizzly |
Key |
Nuts |
||
|
실제 클래스 |
Bauble |
18 |
2 | 2 | 2 | |
|
Beef |
23 |
1 |
||||
|
Grizzly |
24 |
|||||
|
Key |
6 |
18 |
|
|||
|
Nuts |
2 |
22 |
||||
Confusion Matrix 셀 색상은 예측한 뷰 개수(셀 값) / 라벨링한 뷰 총 개수(행 합계)를 나타냅니다. 색이 어두울수록 높은 비율 값을, 밝을 수록 낮은 비율 값을 뜻합니다.
예를 들어, (1,1) 위치에 있는 셀은 어두운 붉은색입니다. 왜냐하면 'Bauble' 라벨을 가진 뷰 중에서 'Bauble'로 분류된 뷰 개수가 18개이고, 이는 'Bauble' 라벨을 가진 모든 뷰의 75%(18/24)나 차지하기 때문입니다.
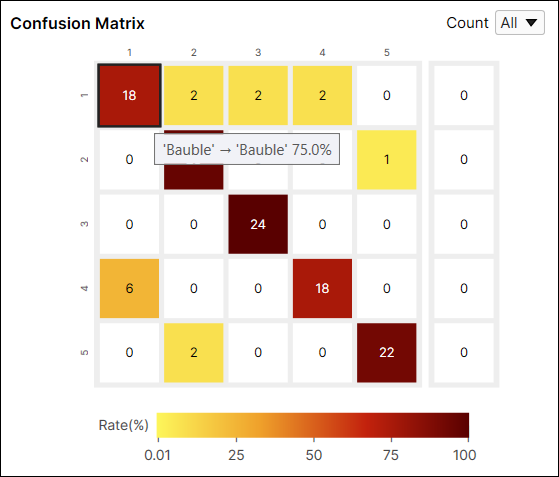
다른 예로, (1,2) 위치에 있는 셀은 노란색입니다. 왜냐하면 'Bauble' 라벨을 가진 뷰 중에서 'Beef'로 분류된 뷰 개수가 2개이기 때문입니다. 'Beef'로 분류된 뷰는 'Bauble' 라벨을 가진 모든 뷰 중에서 단 8.3%(2/24)만 차지합니다.
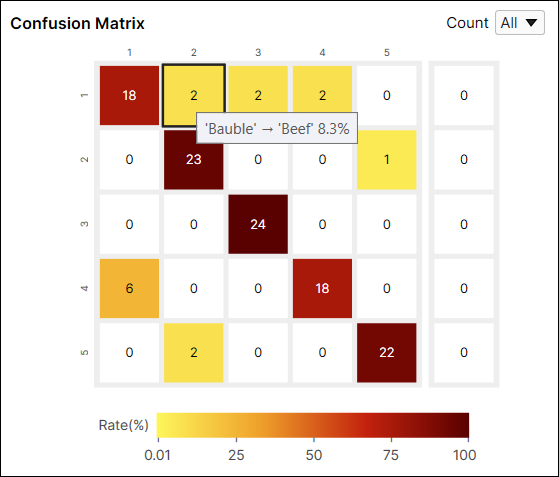
일반적으로 어두운 셀들이 Confusion Matrix 대각선 위치에 나타나는 것이 권장되는데, 이는 바람직한 결과를 얻은 것으로 여겨지기 때문입니다.
|
|
|
| 양호한 성능 |
불량한 성능 |
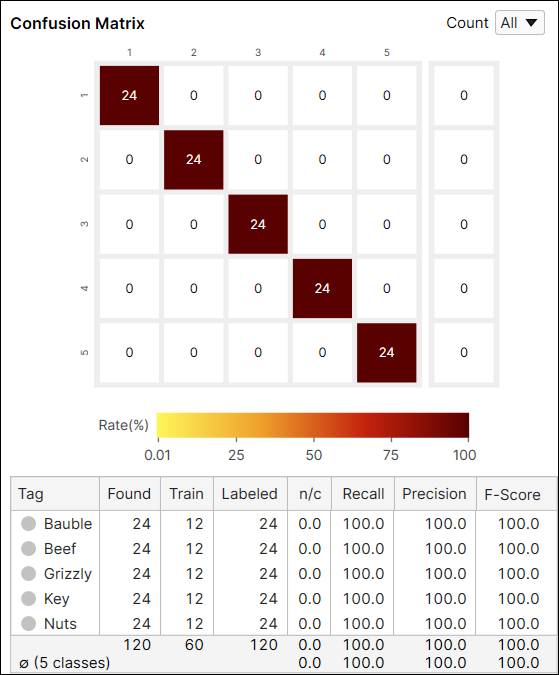
Confusion Matrix 표 변수
| 변수 | 설명 |
| Tag | 클래스 라벨입니다. |
| 찾음 | 이 클래스로 분류(예측, 마킹)된 뷰의 총 개수입니다. |
| 트레이닝 | 이 클래스로 라벨링되었고 트레이닝 세트에 포함된 모든 뷰 개수입니다. |
| Labeled | 이 클래스로 라벨링된 모든 뷰 개수입니다. |
| n/c (분류되지 않음) |
트레이닝 세트에 포함되지 않으며 점수(클래스에 소속될 확률)가 임계치보다 낮은 뷰가 차지하는 비율입니다. |
| Recall |
이 클래스로 라벨링되었고 트레이닝 세트에 포함되지 않은 모든 뷰 중에서 정확하게 분류된 뷰 비율입니다. 자세한 정보는 아래를 확인하십시오. |
| Precision | 이 클래스로 분류되었고 트레이닝 세트에 포함되지 않은 모든 뷰 중에서 정확하게 분류된 뷰 비율입니다. 자세한 정보는 아래를 확인하십시오. |
| F-Score | 위에서 계산한 Precision과 Recall의 조화 평균입니다. |
Confusion Matrix의 숫자 계산: 전체 뷰 vs 학습되지 않은 뷰
Confusion Matrix 카운트 옵션으로 모든 뷰 또는 트레이닝 세트에 포함되지 않은 뷰(트레이닝 되지 않은 뷰)에서만 현재 도구 결과를 확인할 수 있습니다. 학습과 테스트 이미지를 포함한 모든 뷰에 대한 결과를 표시하거나, 학습되지 않은 뷰 즉 테스트 이미지에 대한 결과를 표시할 수 있습니다.
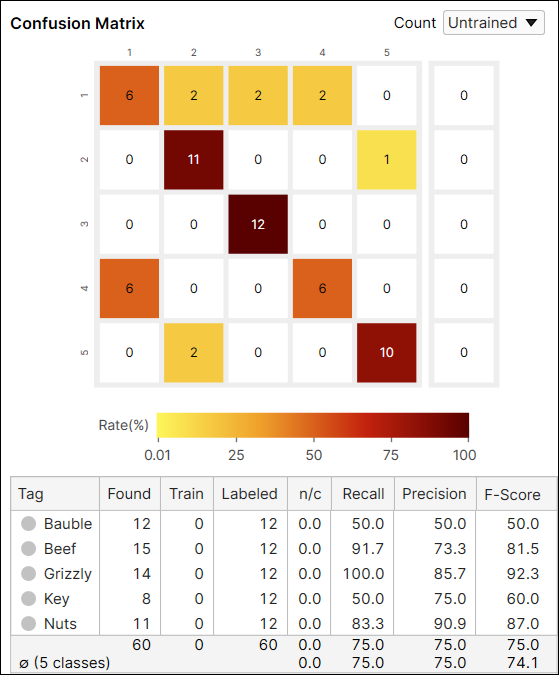
Green 분류 도구의 Precision, Recall, F-Score
Precision과 Recall은 도구를 트레이닝하는 데 사용되지 않은 데이터로 계산합니다. F-Score는 Precision과 Recall의 조화평균이며 따라서 F-Score 또한 트레이닝 데이터 세트에 포함되지 않은 데이터로 계산합니다. 디스플레이 필터를 사용해 Confusion Matrix 표에 나타난 값과 같은 값을 직접 계산할 수 있습니다.
|
예측된 클래스 |
||||||
|
Bauble |
Beef |
Grizzly |
Key |
Nuts |
||
|
실제 클래스 |
Bauble |
18 |
2 | 2 | 2 | |
|
Beef |
23 |
1 |
||||
|
Grizzly |
24 |
|||||
|
Key |
6 |
18 |
|
|||
|
Nuts |
2 |
22 |
||||
-
클래스 "Beef"에서 Precision 계산 예시(디스플레이 필터 구문)
-
True Positives: best_tag='Beef' and tag![name='Beef'] and not trained
-
False Positives: best_tag='Beef' and tag![name!='Beef'] and not trained
-
Precision = True Positives / (True Positives + False Positives)
-
-
클래스 "Beef"에서 Recall 계산 예시(디스플레이 필터 구문)
-
True Positives: best_tag='Beef' and tag![name='Beef'] and not trained
-
False Negatives: best_tag!='Beef' and tag![name='Beef'] and not trained
-
Recall = True Positives / (True Positives + False Negatives)
-
-
클래스 "Beef"에서 F-Score 계산 예시
Precision 계산
Green 분류 도구에서 Precision은 검출된 클래스 전체 중에서 검출된 클래스와 라벨된 클래스와 일치한 경우를 백분율로 계산한 값입니다.
이 도구는 Precision을 실제 클래스 i로 예측된 뷰 중 정확하게 분류된 경우를 백분율로 계산합니다.
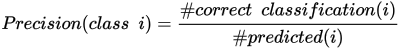
예를 들어, "Breast(가슴살)" 클래스의 Precision이 90%라고 하면, 신경망이 10번 중에 1 번은 Breast(가슴살)을 다른 클래스와 혼동한다는 뜻입니다.
|
예측된 클래스 |
|||||||||||
|
Breast(가슴살) |
Drumstick(다리) |
Filet(살코기) |
Flaps(플랩) |
Leg(다리) |
Neck(목) |
Skewer(꼬치) |
Skliced Breast(저민 가슴살) |
Thigh(허벅지) |
Wings(날개) |
||
|
실제 클래스 |
Breast(가슴살) |
19 |
1 |
||||||||
|
Drumstick(다리) |
14 |
2 |
2 |
2 |
|||||||
|
Filet(살코기) |
20 |
||||||||||
|
Flaps(플랩) |
19 |
1 |
|||||||||
|
Leg(다리) |
18 |
||||||||||
|
Neck(목) |
2 |
17 |
|||||||||
|
Skewer(꼬치) |
1 |
13 |
|||||||||
|
Skliced Breast(저민 가슴살) |
4 |
4 |
14 |
||||||||
|
Thigh(허벅지) |
1 |
2 |
16 |
||||||||
|
Wings(날개) |
20 |
||||||||||
Recall 계산
Green 분류 도구에서 Recall은 라벨된 클래스 중에서 도구에 의해 정확하게 식별된 경우의 백분율을 말합니다.
이 도구는 Recall을 클래스 i로 라벨된 뷰 중에서 도구에 의해 클래스 i로 정확하게 예측된 비율로 계산합니다.
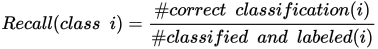
예를 들어, "Breast(가슴살)" 클래스의 Recall이 90%라고 하면, 신경망이 Breast(가슴살)을 정확하게 분류하는 비율이 10번 중 9번이라는 뜻입니다.
|
예측된 클래스 |
|||||||||||
|
Breast(가슴살) |
Drumstick(다리) |
Filet(살코기) |
Flaps(플랩) |
Leg(다리) |
Neck(목) |
Skewer(꼬치) |
Skliced Breast(저민 가슴살) |
Thigh(허벅지) |
Wings(날개) |
||
|
실제 클래스 |
Breast(가슴살) |
19 |
1 |
||||||||
|
Drumstick(다리) |
14 |
2 |
2 |
2 |
|||||||
|
Filet(살코기) |
20 |
||||||||||
|
Flaps(플랩) |
19 |
1 |
|||||||||
|
Leg(다리) |
18 |
||||||||||
|
Neck(목) |
2 |
17 |
|||||||||
|
Skewer(꼬치) |
1 |
13 |
|||||||||
|
Skliced Breast(저민 가슴살) |
4 |
4 |
14 |
||||||||
|
Thigh(허벅지) |
1 |
2 |
16 |
||||||||
|
Wings(날개) |
20 |
||||||||||
F-Score 계산
Green 분류 도구에서 F-Score는 Recall과 Precision 값의 조화 평균입니다. F-Score는 도구의 전체적 정확도를 가장 잘 나타내는 지표로 간주됩니다.
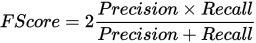
도구를 최적화할 때, 다음을 고려하십시오.
- False Positive를 절대적으로 피하려면, Precision 값 100을 목표로 하십시오.
- False Negative를 절대적으로 피하려면, Recall 값 100을 목표로 하십시오.
그렇지 않다면, 다음을 목표로 하십시오.
- 샘플수가 적은 클래스가 있어서 클래스 불균형 문제가 있는 경우, F-Score를 기준으로 판단하십시오.
- 모든 클래스에 대해 평균을 낸 F-Score를 이용하십시오.
- 분류되지 않은 뷰의 비율이 달라지는 것을 피하려면, 임계치 프로세싱 매개변수를 0%로 설정하십시오.