속도 최적화
이 섹션에서는 VisionPro Deep Learning 응용 프로그램의 프로세싱 시간을 줄이는 데 유용한 팁과 기법을 알아봅니다.
도구 및 스트림 프로세싱 시간
개별 도구의 프로세싱 시간은 아래와 같이 데이터베이스 개요에 표시됩니다:
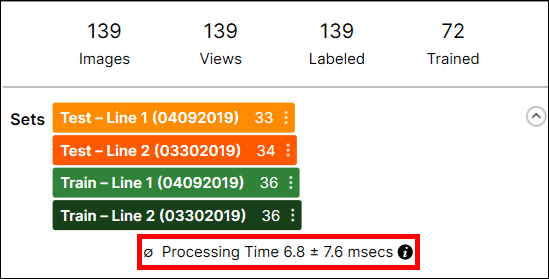
프로세싱 시간은 프로세싱 시간과 사후 프로세싱 시간이 더해진 시간입니다.
다수 도구를 포함하는 스트림의 프로세싱 시간은 VisionPro Deep Learning GUI에서 제공되지 않으며, 스트림 내에 있는 도구의 실행 시간을 합산하여 추정할 수 없습니다. 프로세싱 시간에는 도구 간에 뷰를 준비하고 전송하는 시간이 포함되기 때문입니다.
스트림 프로세싱을 고려할 때는, Stream.Process()를 호출하면, 스트림 내의 도구 프로세싱이 항상 직렬화된다는 점을 기억하십시오. Tool.Process()를 이용해 명시적으로 도구를 개별 프로세싱하지 않는 이상, 어떤 시점에도 하나의 도구만이 프로세싱됩니다.
프로세싱 양
VisionPro Deep Learning에서, 프로세싱 양은 단위 시간당 프로세싱할 수 있는 전체 이미지 수를 말합니다. 응용 프로그램이 다른 스레드를 이용해 다수의 스트림을 동시에 프로세싱할 수 있다면, 시스템 프로세싱 양을 늘릴 수는 있지만, 개별 도구의 프로세싱은 느려질 수 있습니다.
소프트웨어: 매개변수 최적화
이 섹션에서는 성능을 최대화하기 위해 다양한 VisionPro Deep Learning 도구의 매개변수를 최적화하는 방법을 설명합니다.
| 매개변수 | Feature Size(Feature 크기) | Sampling Density(샘플링 밀도) | 색상 채널 | Precision | 반복 |
|---|---|---|---|---|---|
| 도구 | 위치, 분석, 분류 | 위치, 분석, 분류 | 위치, 분석, 분류 | Blue | Red |
| 프로세싱 시간 |
|
|
|
|
|
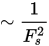
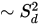
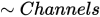
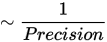
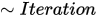
도구 매개변수 선택은 도구의 실행 속도에 직접 영향을 미치지만, 도구 속도와 정확도 또는 안정성 사이에는 상충 관계가 있습니다.
| VisionPro Deep Learning 도구 매개변수 | 속도에 영향을 미치는 방식 | 최선의 대안 | 주의 사항 |
|---|---|---|---|
| 아키텍처 | High Detail 모드의 프로세싱 시간은 사후 처리 및 사전 처리 로직의 차이로 인해 Focused 모드(그리고 SuaKIT Segmentation/Classification 프로젝트) 프로세싱 시간보다 약간 길 수 있습니다. | ||
|
Feature 크기 (Focused 모드) |
Deep Learning 도구는 런타임에 input 이미지 전체를 샘플링해야 합니다. Feature 크기는 주어진 이미지 크기에 대해 필요한 샘플의 수를 결정합니다. Feature 크기가 크면, 샘플 수가 줄어듭니다. |
Feature 크기가 크면 O(n2)는 속도가 증가합니다. |
Feature 크기가 커지면 도구가 feature가나 결함을 놓치는 원인이 됩니다. Parameter Search 매개변수 최적화 유틸리티를 이용해 최적의 feature 크기를 찾습니다. |
|
샘플링 밀도 (Focused 모드) |
Feature 크기와 비슷하게, 샘플링 밀도도 주어진 이미지 크기에 대해 필요한 샘플의 수를 결정합니다. |
샘플링 밀도가 낮으면 O(n2)는 속도가 증가합니다. |
Feature 또는 결함을 놓칠 위험. |
|
개선 매개변수 |
Blue 위치 및 Red 분석 도구에는 다음의 프로세싱 시간 매개변수가 있어 실행 속도가 늘어나는 대신 더 정확한 결과를 얻을 수 있습니다.
|
Iterations 값을 늘리면, 프로세싱 시간이 비례적으로 증가합니다. |
|
|
낮은 Precision (Focused 모드) |
시스템이 특정할 구체적 요건(CUDA 컴퓨팅 역량 6.1 이상)을 충족하는 경우, Red 분석 및 Green 분류 도구에 낮은 Precision 프로세싱 모드를 활성화할 수 있습니다. 낮은 Precision 모드를 활성화하면 기존에 트레이닝된 도구가 프로세싱 중 낮은 Precision 계산 모드를 이용하도록 전환되고, 비활성화될 때까지 미래의 모든 트레이닝 작업에 낮은 Precision 도구를 생성합니다. Note: 도구가 낮은 Precision 모드를 사용하도록 전환된 후에 낮은 Precision 모드를 비활성화하려면, 다시 트레이닝해야 합니다. 낮은 Precision 도구는 정상 Precision 도구보다 25%에서 50%까지 실행 속도가 빠를 수 있습니다.
|
낮은 Precision 도구의 추가적인 런타임 속도 향상은 튜링 텐서 코어가 있는 시스템에서 보입니다. | 도구가 낮은 Precision 모드를 이용하도록 변경하면, 해당 도구가 산출하는 결과에 약간의 영향이 있습니다. 일반적으로 고수준의 feature 식별, 결함 분류, 일반적인 분류는 변함이 없지만, 특정 feature 및 결함 영역 및 점수는 조금 변경될 수 있습니다. |
Feature 크기 최적화
Feature 크기는 프로세싱 시간(n2)에 큰 영향을 미칩니다. Feature 크기가 100이면 10일 때에 비해 100배 빠르며, 15 이하의 feature 크기는 대개 좋은 결과를 얻지 못합니다.
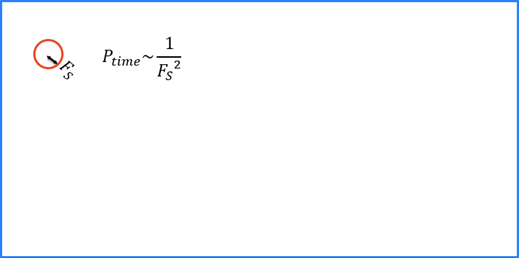
트레이닝 및 런타임 모두, 각 Deep Learning 도구는 이미지 전체를 완전히 커버할 수 있는 이미지 샘플을 수집합니다.
Feature 크기는 실행 시간에 직접 연관되며, 도구 트레이닝 시간에는 영향이 적습니다. Feature 크기가 크면 프로세싱이 훨씬 신속해지지만, 작은 feature는 "보지" 못하거나 "대응하지" 못할 수 있습니다.
해당 도구는 트레이닝 중에 input 이미지의 전체 범위를 샘플링하는데, 정보가 더 많다고 판단한 영역에서는 샘플을 과다하게 추출합니다.
샘플링 밀도 최적화
샘플링 밀도 매개변수는 이미지를 얼마나 조밀하게 샘플링할지 결정합니다. 이 숫자가 작을수록, 이미지에서 적은 수의 샘플을 추출합니다.
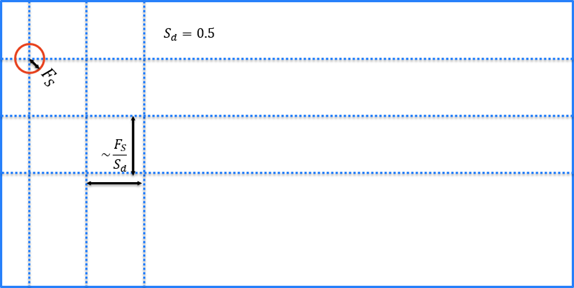
0.5의 샘플링 밀도 설정은 1의 설정보다 4배[0(n2)] 빠릅니다.
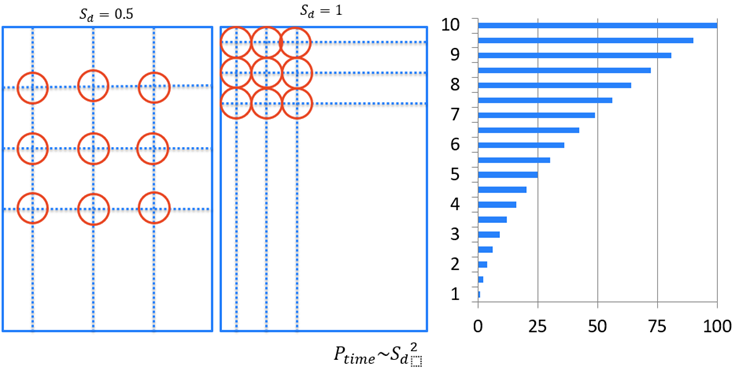
컬러 채널 최적화
응용 프로그램이 컬러 이미지에 의존하면, 가능한 한 최소의 필요 색상 채널을 이용하고, 이미 정확한 수의 채널을 갖고 있는 이미지만을 전송해 변환을 회피하십시오. 이는 다음 때문입니다.
Precision 최적화
Blue Locate에는 Precision이라는 고유의 매개변수가 있는데, 이는 도구가 원하는 위치 Precision에 이르면 feature 찾기를 종료하라고 지정하기 위해 이용됩니다. 이는 탐색 대상인 feature 크기의 백분율로 설정됩니다.
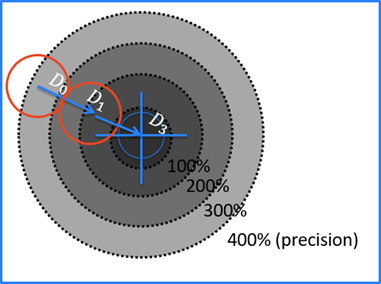
Precision이 400%라면, 위치 도구는 D0에서 멈춥니다.
200 %: D1
100%: Precision과 일치
중지 기준: 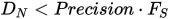
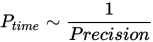
Iteration 최적화
전문가 모드에 있을 때는 Red Analyze 도구 비지도 모드에서 추가적으로 Iterations 매개변수를 이용할 수 있습니다. 이 매개변수는, 관심 영역(ROI)에서 분석 결과를 국지적으로 개선하기 위해 도구가 얼마나 추가적으로 반복 실행할지를 지정합니다.
소프트웨어: 관심 영역(ROI) 최적화
관심 영역(ROI)를 구성할 때, ROI는 최대한 작게 생성하십시오. 또한, Red Analyze 이용 시에는, 이미지에서 응용 프로그램에 연관되지 않은 모든 것을 마스킹하십시오.
하드웨어: GPU 최적화
다음은 Windows에서 그래픽 드라이버 모드 선택 시 고려할 사항입니다.
Tesla 컴퓨터 클러스터(TCC)
- NVIDIA RTX / Quadro®, Tesla®, GeForce® GTX TITAN만 적용(NVIDIA와 공식적으로 소통한 사항은 아님).
- GPU는 디스플레이에 이용할 수 없습니다.
- NVIDIA RTX / Quadro®의 기본 모드는 WDDM입니다.
Windows 디스플레이 드라이버 모델(WDDM)
- NVIDIA GeForce® 또는 NVIDIA RTX / Quadro®.
- GPU는 디스플레이 출력 및 계산에 공유됩니다.
메모리 배정 시간
- WDDM >> TCC
다수 GPU 구성 개선
- WDDM << TCC
해결 방안:
- NVIDIA 프로페셔널 또는 GeForce® GTX TITAN 카드만 TCC로 이용합니다.
- VisionPro Deep Learning GPU 메모리 최적화 기능을 사용하십시오.
GPU 메모리 최적화

VisionPro Deep Learning 메모리 사용:
- 표시: 계산 전에 이미지를 저장하는 메모리
- VisionPro Deep Learning 예약: 계산을 위해 예약된 메모리
- 사용 가능: 메모리 양을 알 수 없어 사용 가능한 상태로 남겨진 메모리
트레이닝의 예:
- 예약 메모리 2.0GB(트레이닝의 최소값)
- 사용 가능 메모리 약 1GB
- 메모리가 3.5GB 이상인 그래픽 카드가 필요합니다
런타임의 예:
- 예약 메모리 512MB
- 사용 가능 메모리 256MB
- 필요 최소 메모리가 없는 그래픽 카드라도 됩니다
GPU 메모리 최적화 기능(2GB의 기본값으로 활성화되어 있음)을 이용하면, Windows 디스플레이 드라이버 모델(WDDM)과 Tesla 컴퓨터 클러스터(TCC) 드라이버의 성능이 현저하게 개선됩니다. 하지만 응용 프로그램에 따라 예약 메모리를 신중하게 선택해야 합니다. 작은 이미지를 프로세싱하는 응용 프로그램의 경우 성능이 가장 크게 개선됩니다.
| 장점 | 단점 |
|---|---|
|
그래픽 카드의 메모리 예약 |
예약할 메모리의 정확한 양을 추정하기 어려움 |
|
메모리 할당에 낭비되는 시간 없어짐 |
-
이 옵션을 켜면 시스템이 도구 최적화를 위해 GPU 메모리를 미리 할당합니다. Focused 모드 도구 (Red 분석 도구의 Focused-Supervised / Unsupervised, Blue 위치 , Blue 읽기, Green 분류 도구의 Focused)를 사용하여 트레이닝 및 프로세싱 속도를 높일 때 이 옵션을 켜는 것이 좋습니다.
-
이 옵션을 끄면 시스템이 GPU 메모리의 사전 할당을 중지합니다. High Detail 모드들을(Green 분류 도구의 High Detail 모드, Red 분석 도구의 High Detail 모드, Green 분류 도구 High Detail Quick 모드 모드) 트레이닝 하는 경우이 옵션을 끄는 것이 좋습니다.
이 기능은 API 또는 command line 인수를 이용해 비활성화하거나 할당 설정을 변경할 수 있습니다.
예를 들어, .NET API에서는 control.OptimizedGPUMemory(2.5*1024*1024*1024ul);로 설정하고, C API에서는 vidi_optimized_gpu_memory(2.5*1024*1024*1024);라고 설정할 수 있습니다.
런타임 성능 추정
다음 수치는 다양한 카드군별로 런타임 성능 향상 잠재력에 대한 대략적 지침입니다(기준 = 텐서 코어가 아닌 경우, 표준 모드)
| Deep Learning 작동 모드 |
텐서 코어 없음 (예: GTX) |
Volta Tensor Cores(볼타 텐서 코어) (예: V100) |
Turing Tensor Cores(튜링 텐서 코어) (예: T4) |
|---|---|---|---|
|
표준 |
100% |
150% |
150% |
|
Low Precision(낮은 Precision) |
125% |
125% |
175% |