查看参数搜索结果
参数搜索实用程序完成参数设置网格的计算后,您可以查看结果来确定应用程序的最佳组合。查看结果的 2 个关键部分:结果表和图形。
查看结果
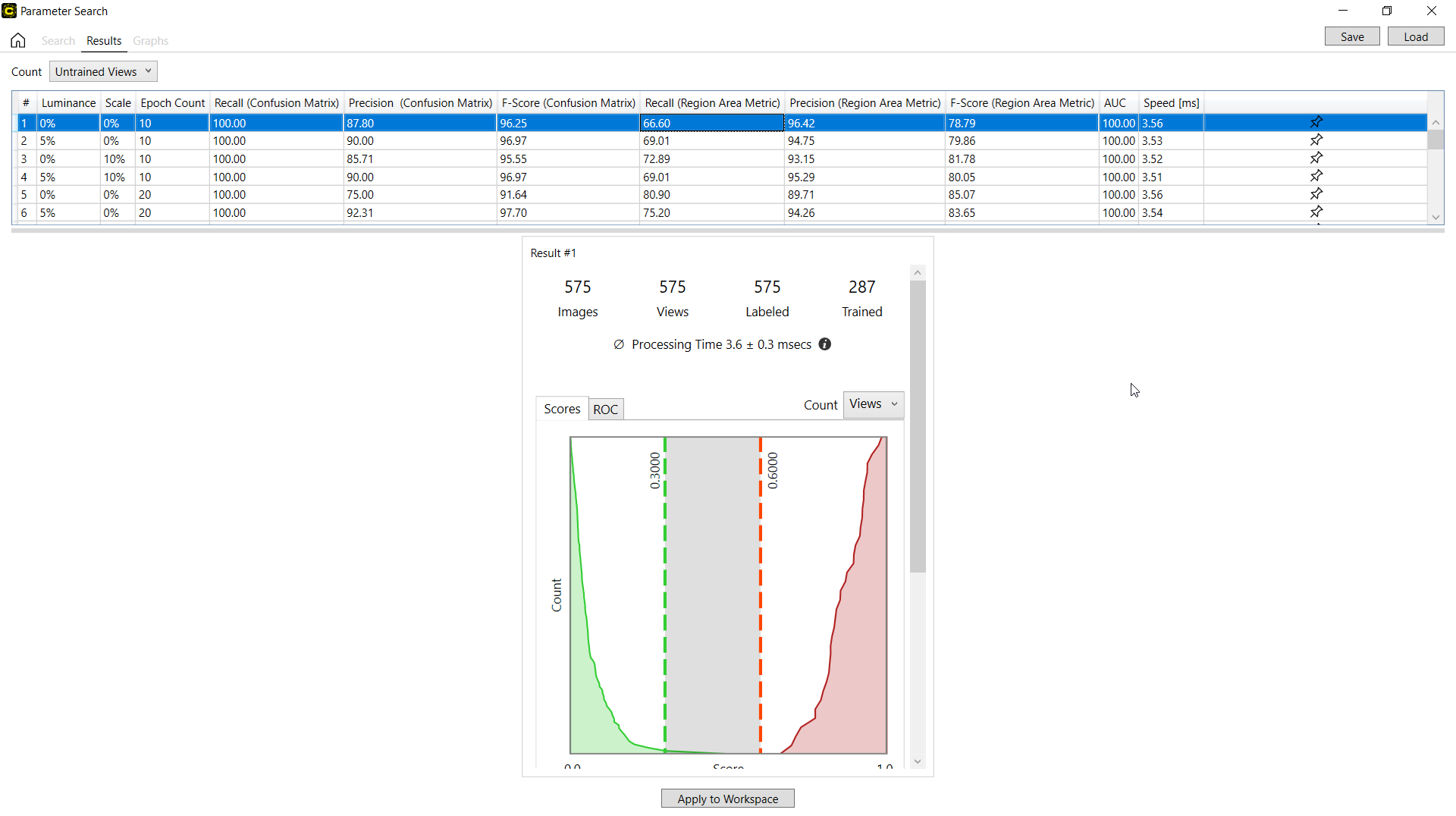
搜索完成后,您可以在“结果”页面上调查参数搜索的结果。搜索结果显示在结果表中。该表的每一行描述了被测试的每个参数组合的值,以及测试结果(F-得分、AUC 等),它们因工具类型而异。对于此表的每一行,您都可以投影一个数据库概述,该概览使用混淆矩阵来制定搜索结果。
|
结果表统计
结果表描述了每种工具类型的结果统计信息:
| 红色分析 | 绿色分类 | 蓝色定位和蓝色读取 |
|---|---|---|
|
精度(混淆矩阵) |
F-得分 |
已找到(特征) |
|
召回(混淆矩阵) |
F-得分(平均) |
精度(特征) |
|
F-得分(混淆矩阵) |
AUC |
召回(特征) |
|
精度(区域面积指标) |
速度 [ms] |
F-得分(特征) |
|
召回(区域面积指标) |
已找到(模型) | |
|
F-得分(区域面积指标) |
精度(模型) | |
| AUC |
召回(模型) |
|
|
速度 [ms] |
F-得分(模型) |
|
| 特征位置距离 | ||
| 特征尺寸差别 | ||
| 特征角度差别 | ||
| 速度 [ms] |
红色分析的搜索结果
红色分析工具的搜索结果包括区域面积指标(按像素计算的精度、召回、F-得分,仅适用于红色分析监督、红色分析高细节、红色分析高细节快速)和混淆矩阵的指标(从混淆矩阵项计算出的精度、召回、F-得分)。有关搜索结果的解释,请参见红色分析工具 - 统计 - 区域面积指标和红色分析工具 – 统计 – 混淆矩阵。
|
|
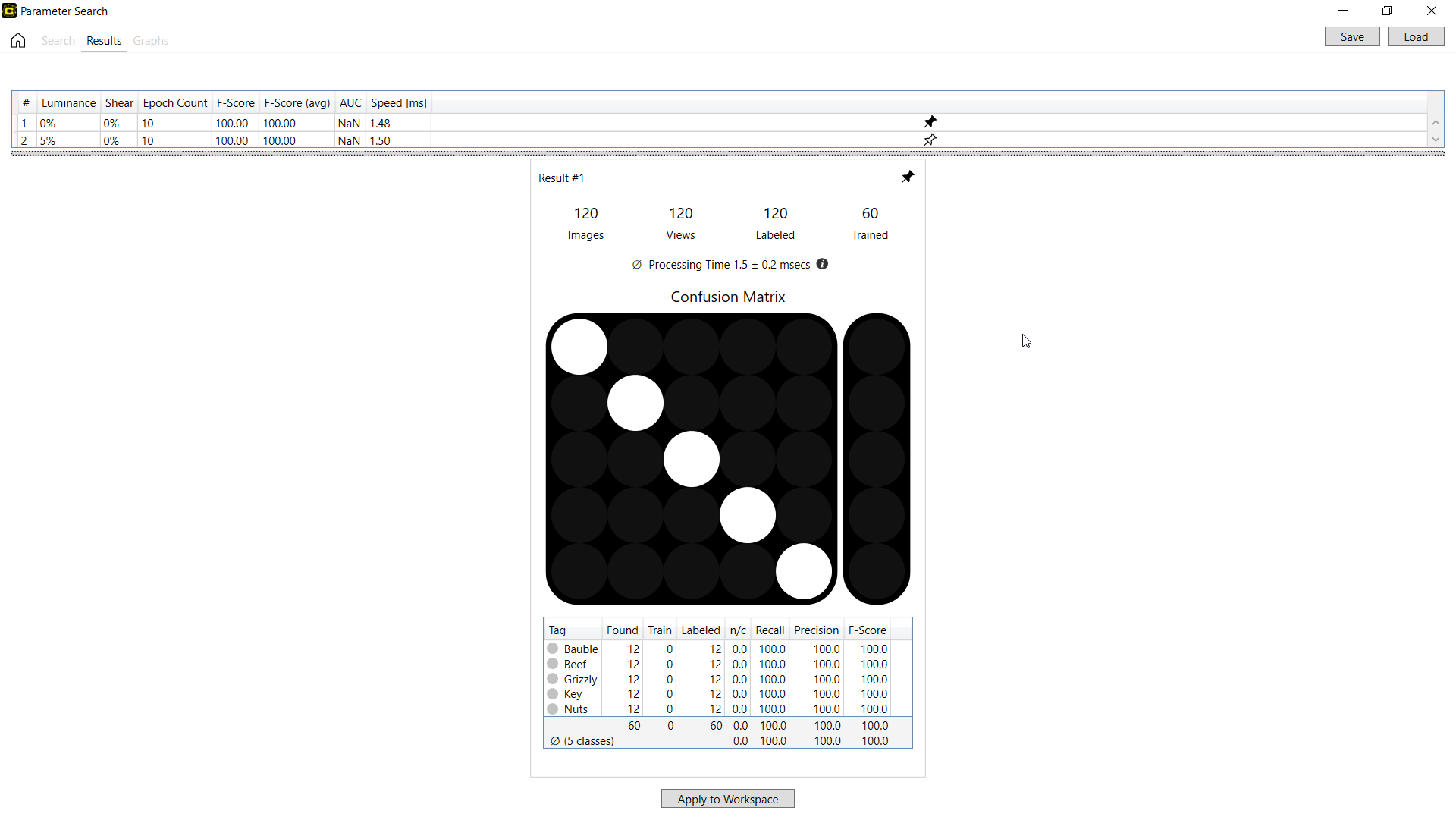
绿色分类的搜索结果
绿色分类工具的搜索结果包括分类性能指标,包括 F-得分(平均)和 F-得分。有关详细信息,请参见绿色分类工具 – 统计。F-得分(平均)是为每个类计算的 F-得分的平均值。
|
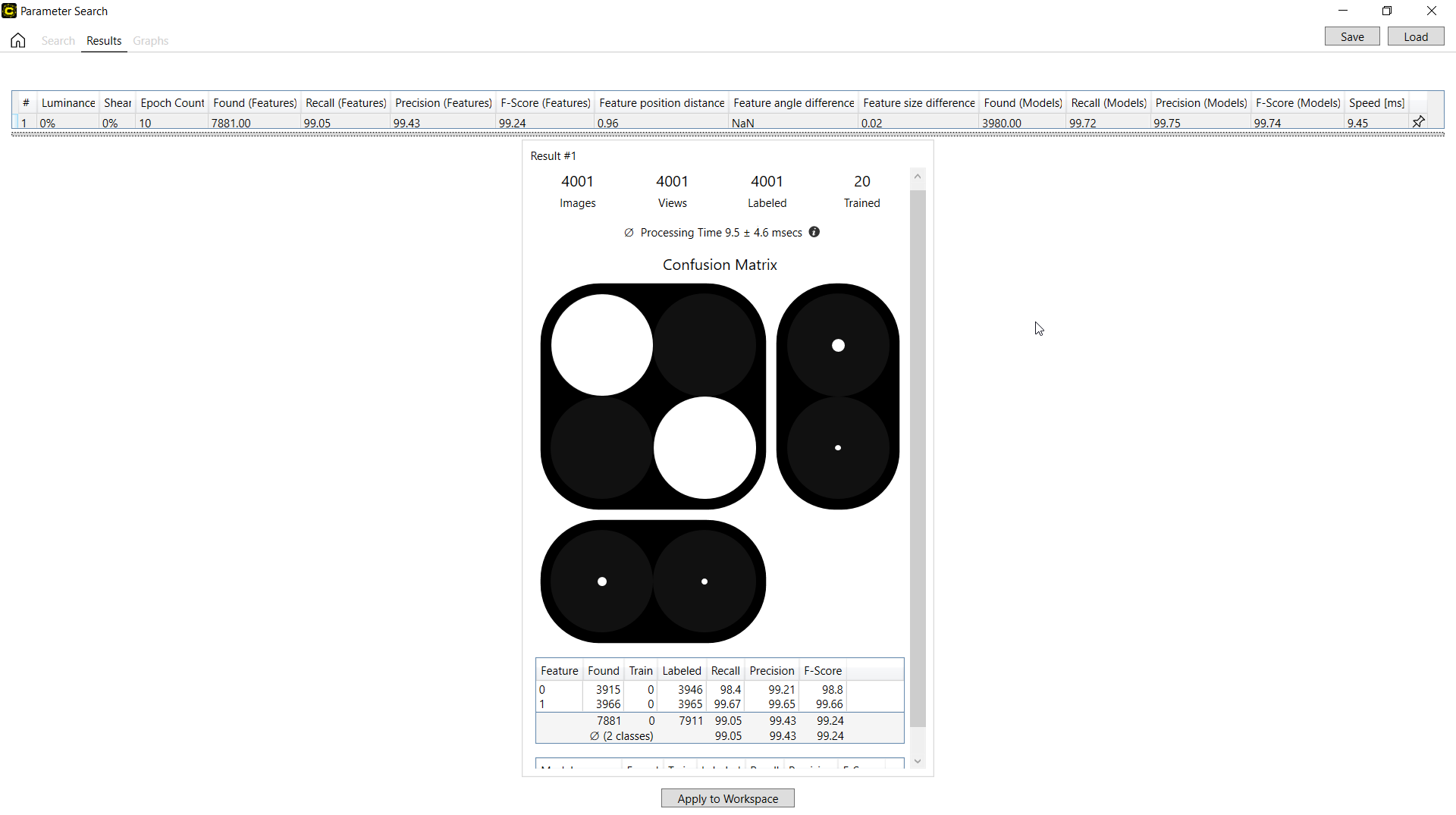
蓝色定位/读取的搜索结果
蓝色定位/读取工具的搜索结果包括特征指标(按特征计算的精度、召回、F-得分)和模型指标(按模型计算的精度、召回、F-得分)。有关详细信息,请参见蓝色定位工具 - 统计和蓝色读取工具 – 统计。
还有其他蓝色定位/读取结果指标,目前仅显示在参数搜索实用程序中。
-
特征大小差别
-
特征角度差别
-
特征位置距离
对于蓝色定位/读取,如果存在相对接近的标注特征,则认为已正确找到(标记)找到的特征。对于每个正确找到的特征,您可以通过将正确找到的特征与标注的特征进行比较来计算位置距离、角度差和大小差。结果表中报告的特征位置距离、特征角度差和特征尺寸差分别为“平均特征位置距离”、“平均角度差”和“平均尺寸差”(均方根平均值),这是分别计算所有正确找到的特征得到的结果。
| 指标 | 说明 |
| 特征大小差别 | 正确找到的特征和标注的特征之间的特征大小差 |
| 特征角度差别 | 正确找到的特征和标注的特征之间的特征角度差 |
| 特征位置距离 | 正确找到的特征和标注的特征之间的特征位置差 |
|
步骤
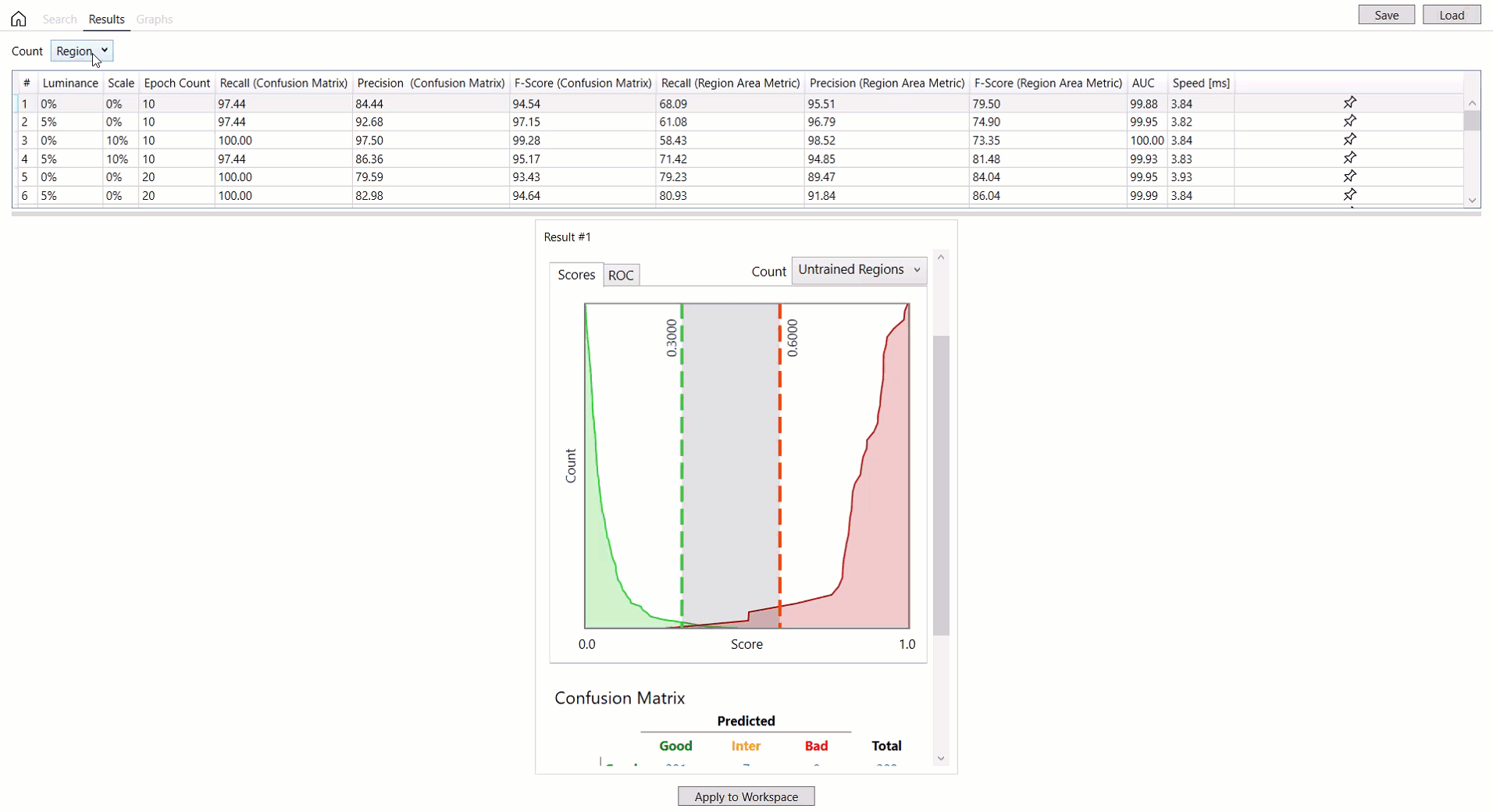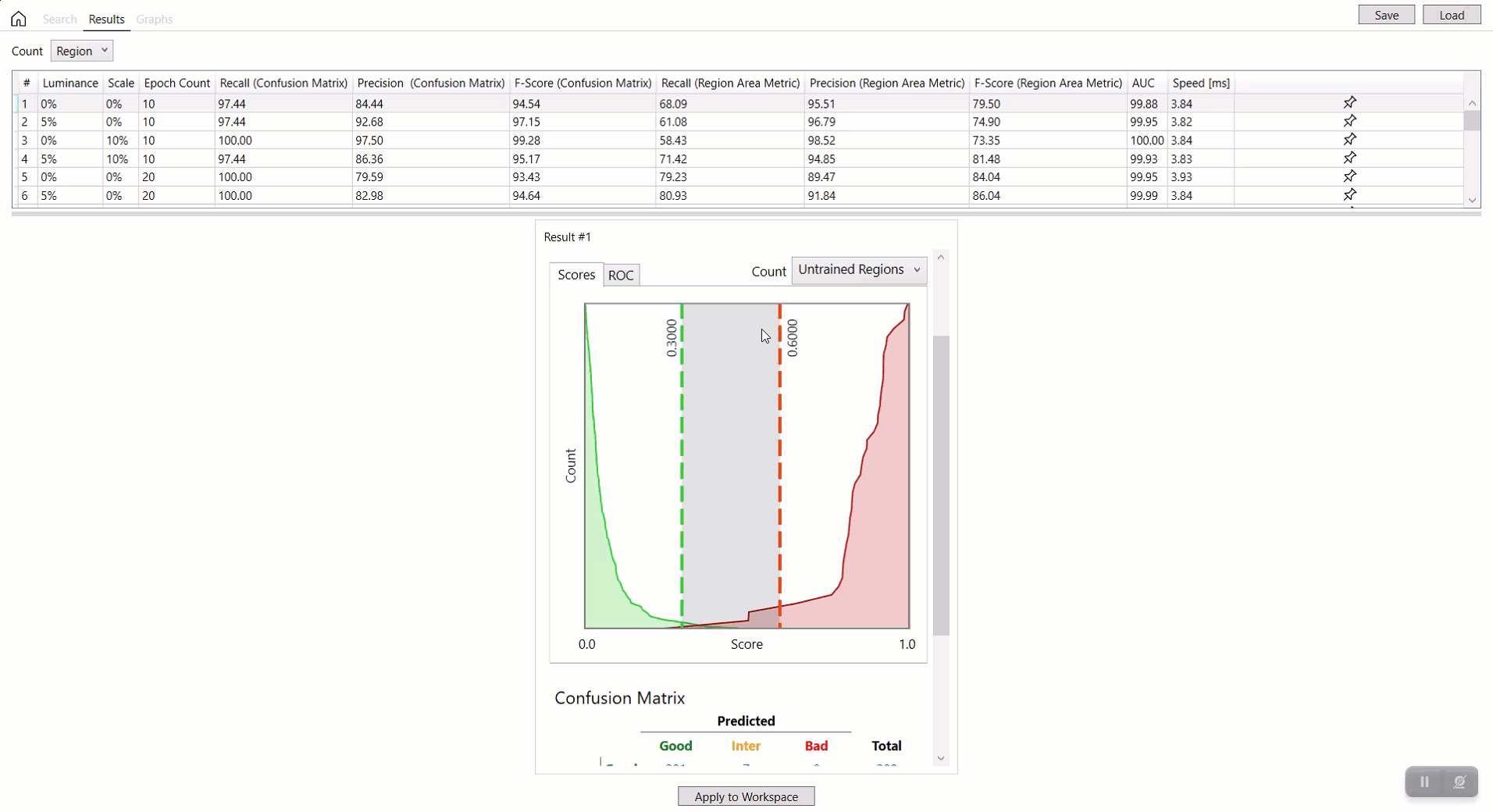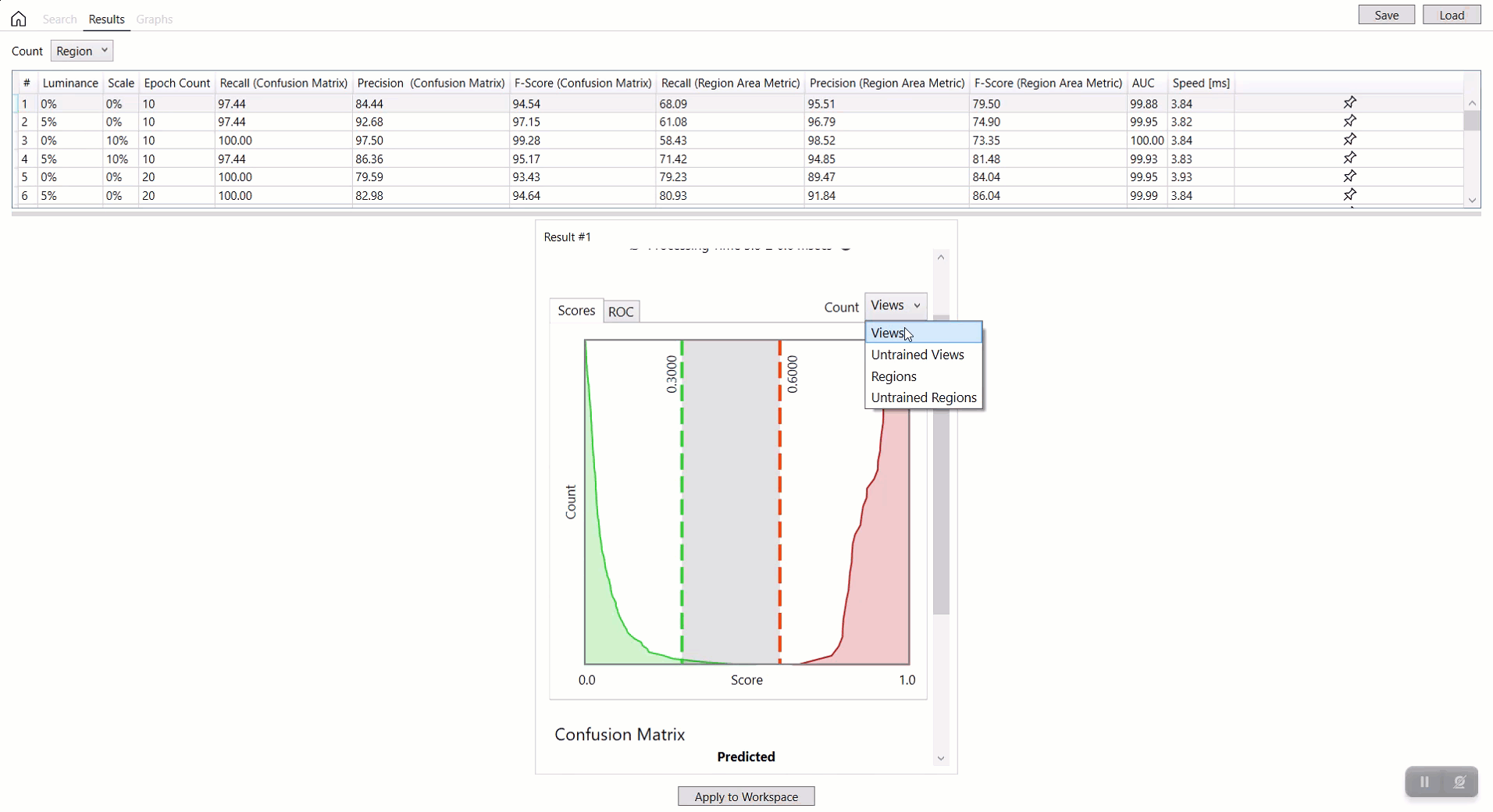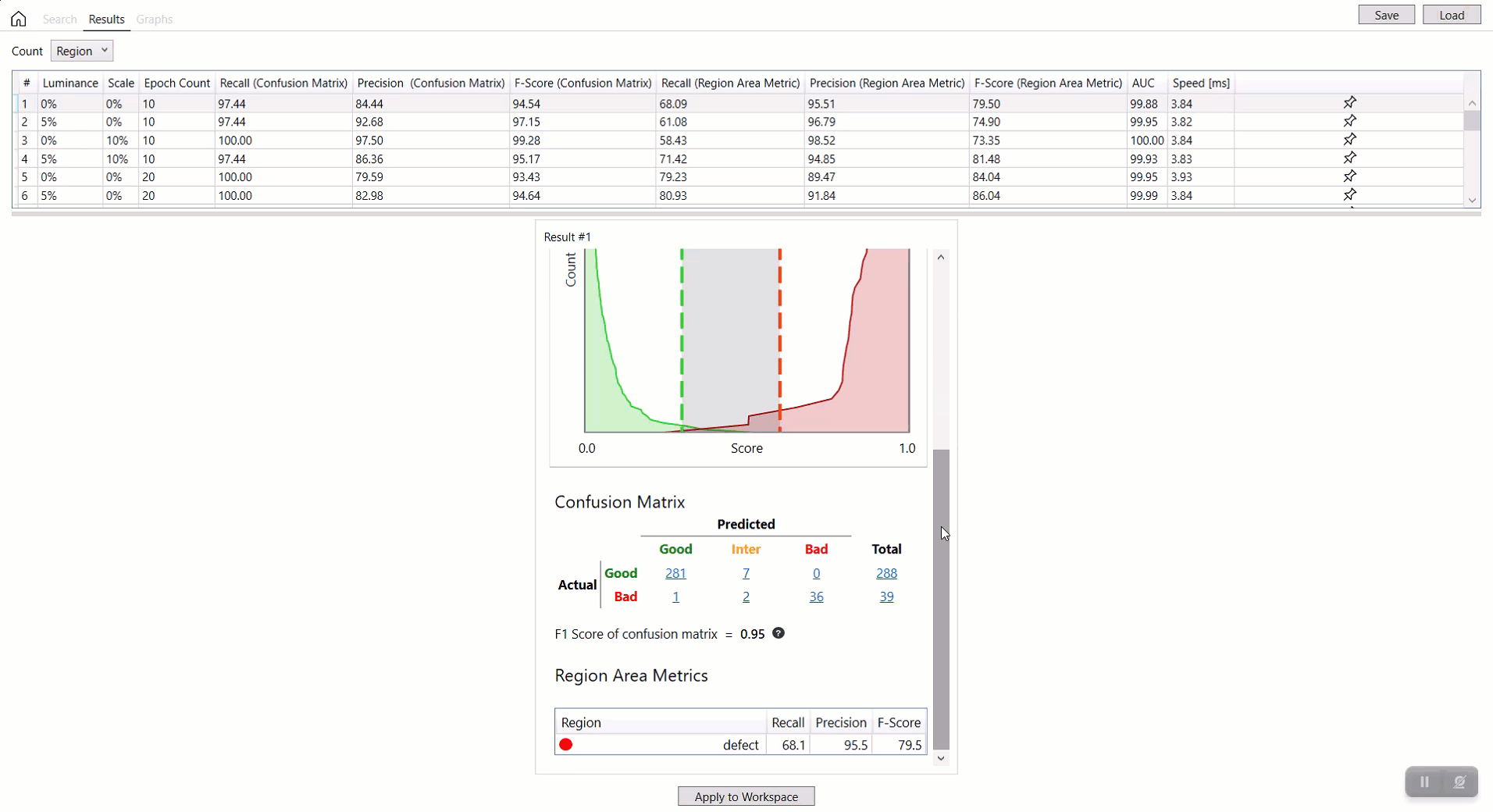
-
在单击结果表中的行时,将选择一行,并且与该行的搜索结果对应的带有混淆矩阵的数据库概述将显示在屏幕底部的最左侧。
-
数据库概述与 Cognex Deep Learning Studio 中的相同。有关解释数据概述中结果的信息,请参见统计。
-
对于红色分析工具,可以应用计数下拉选项(视图、未训练视图、区域、未训练区域)来按每个方面投影数据库概述。有关每个选项的详细信息,请参见红色分析工具 – 统计 – 混淆矩阵。
-
-
单击固定
png.png) 以固定行的数据库概述。最多可同时修复 2 个数据库概述。单击
以固定行的数据库概述。最多可同时修复 2 个数据库概述。单击png.png) 图标以从下面的面板中释放数据库概述。
图标以从下面的面板中释放数据库概述。-
每个选定行的数据库概述将被固定在下方面板的最左侧,1 个或多个固定的数据库概述将被固定在其右侧。
-
如果单击每个固定的数据库概述上的
图标,它将从面板中释放。
-
-
选择结果表中的行后,单击应用到工作区以在加载的工作区中应用选定的参数集和经过训练的工具(神经网络模型)。当前加载的工作空间中的工具参数值和工具本身将替换为结果表中选定行中的参数值。
在加载的工作区中应用后,您现在可以访问该工具及其训练结果VisionPro Deep Learning。在Cognex Deep Learning Studio中,打开工作区并处理该工具,您将获得在参数搜索中产生的相同结果。
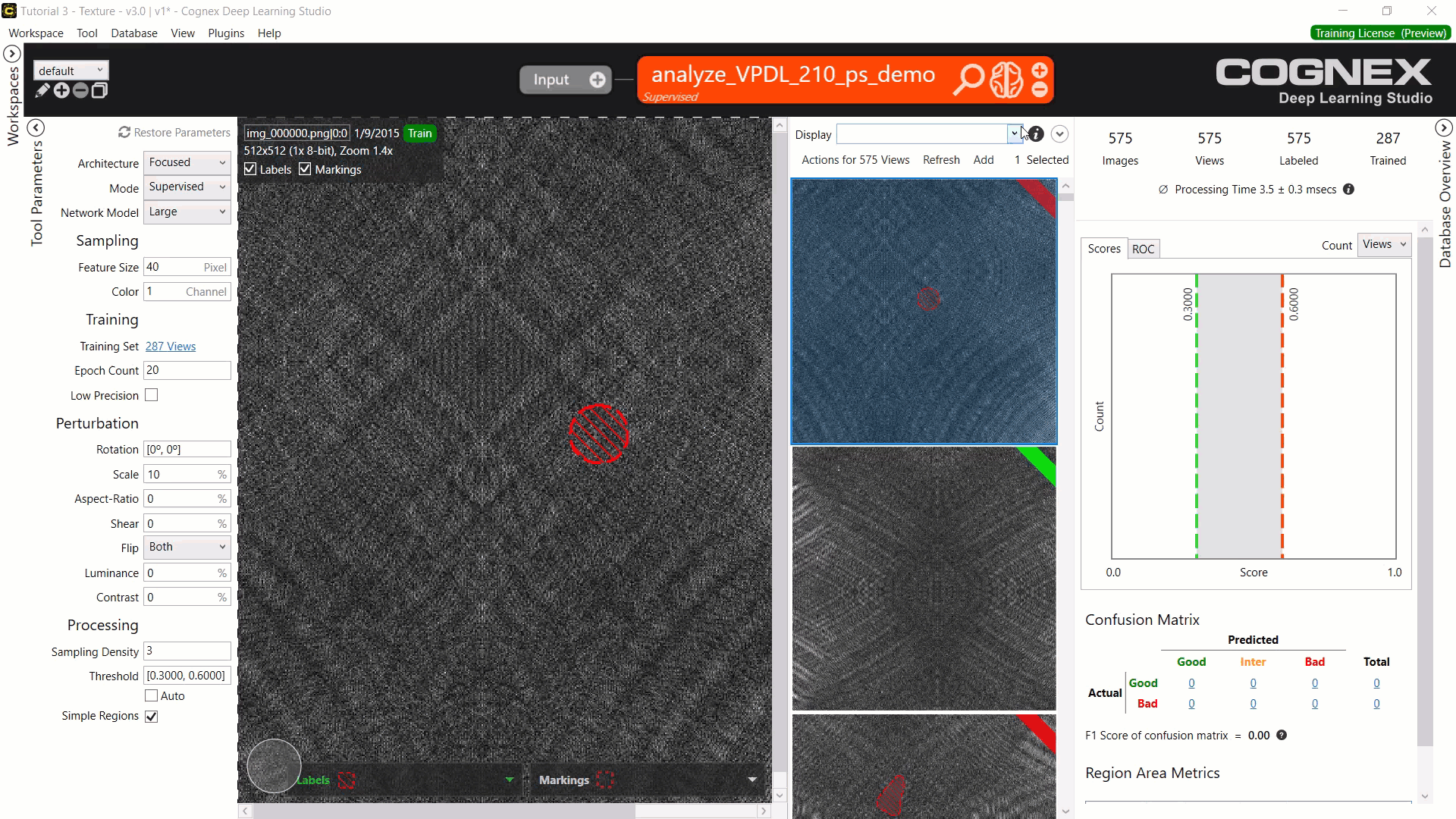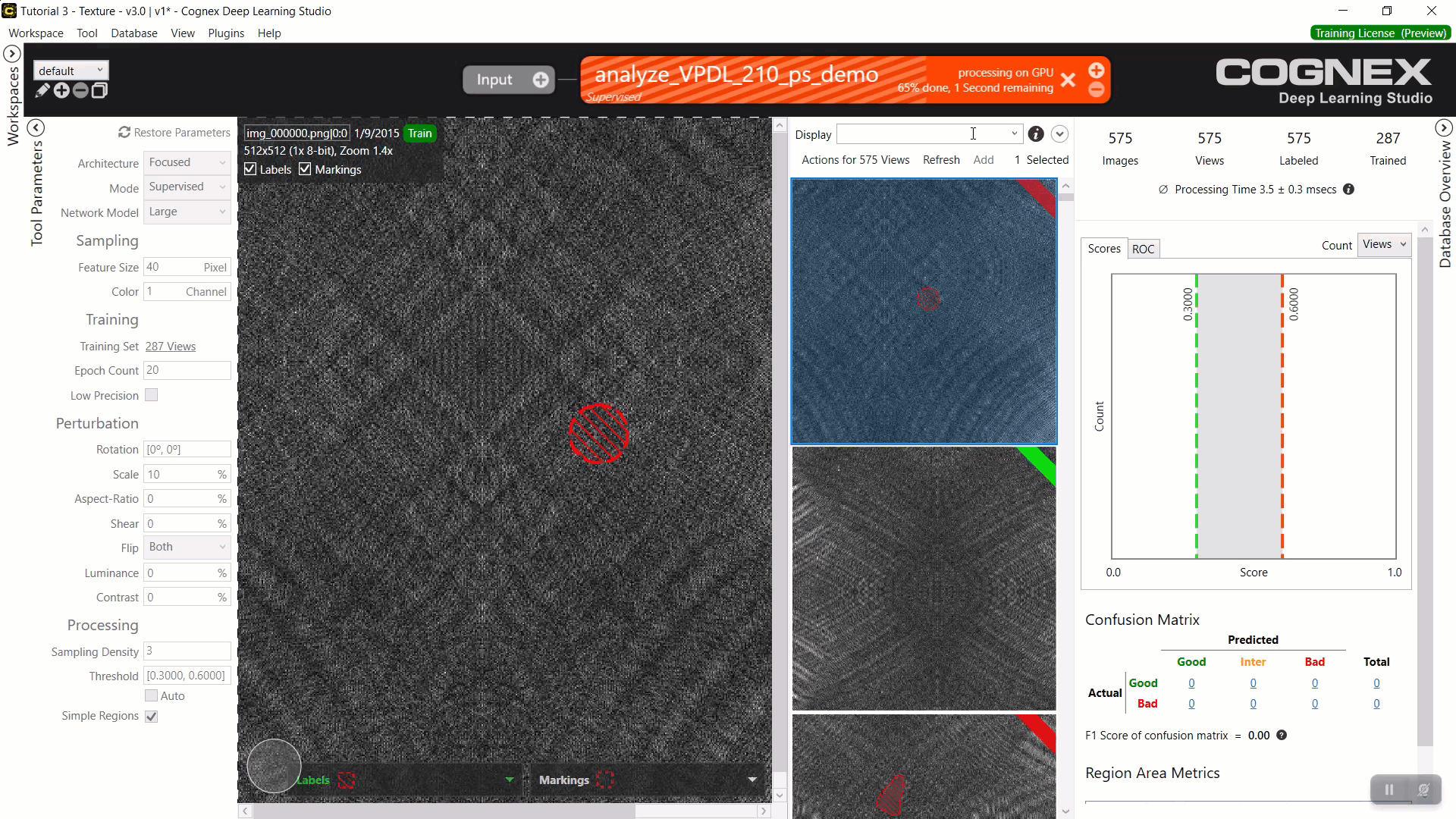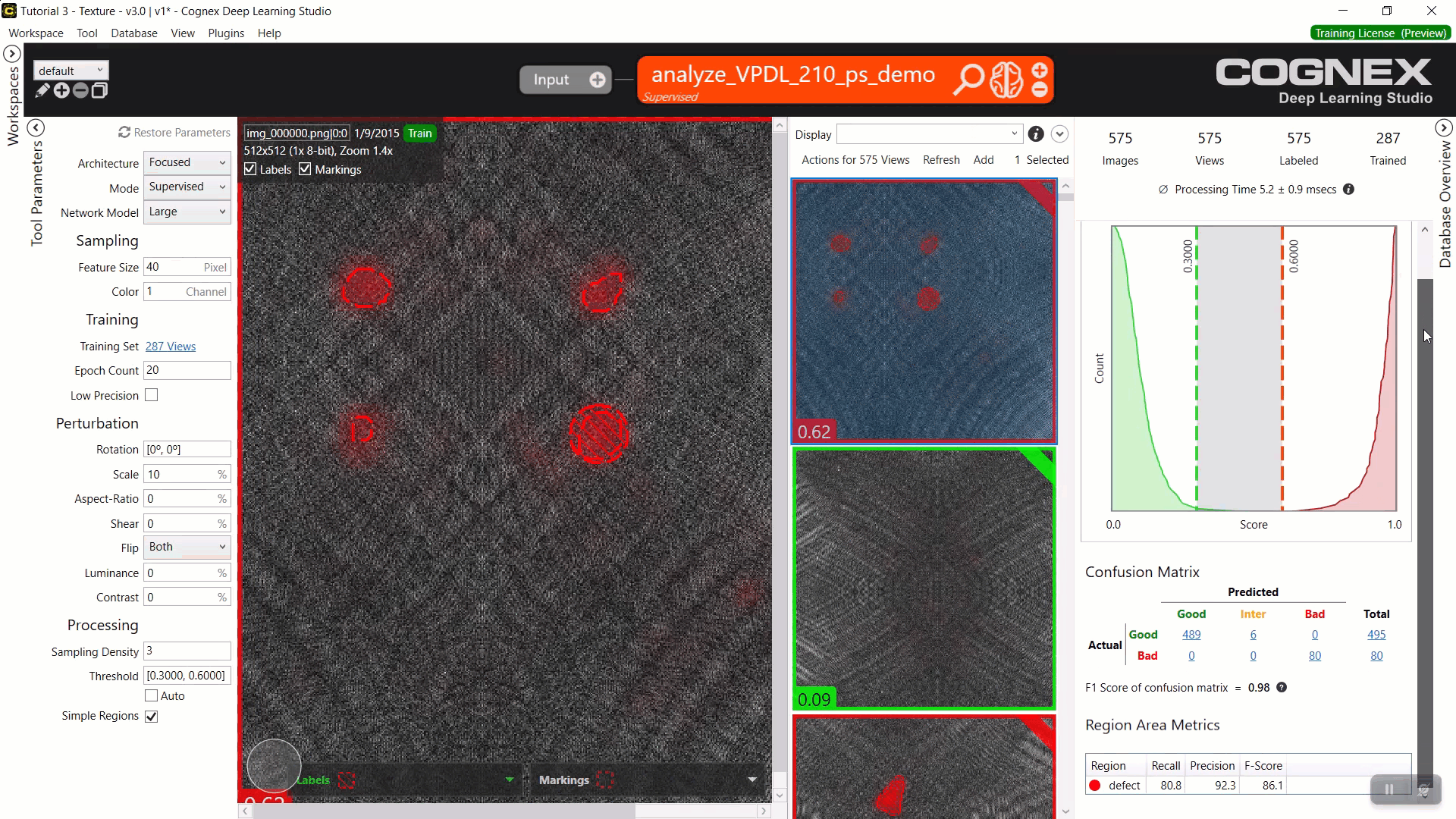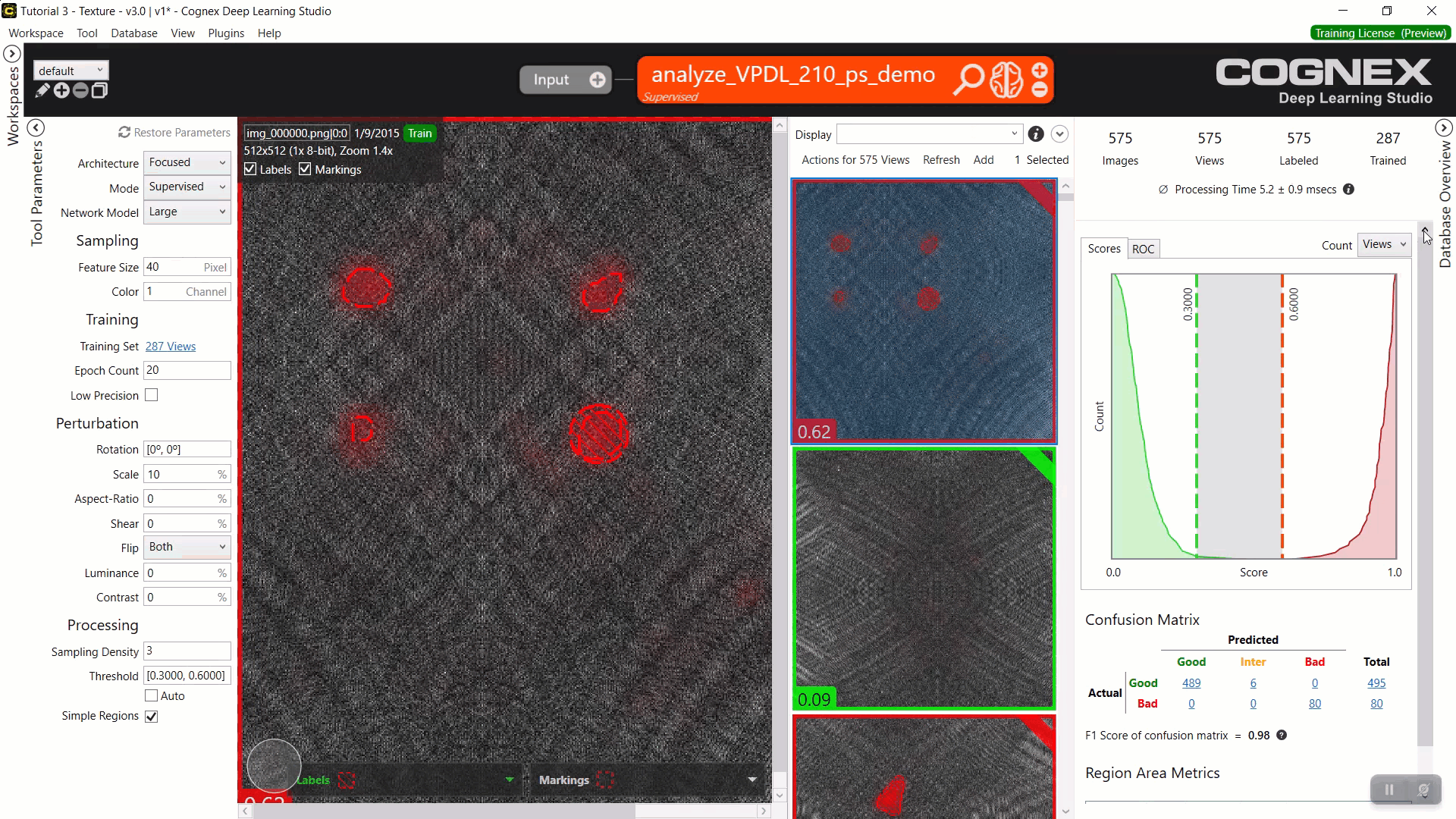
注意:由于之前保存的参数搜索数据 XML 文件不包含经过训练的网络(经过训练的工具),因此您无法将应用到工作区与加载的参数搜索数据 XML 文件一起使用。要将之前保存的搜索结果应用到您的工作区,您必须在开始搜索之前通过启用“搜索”页面中的保存工具复选框来保存包含经过训练的网络的工具文件来保存经过训练的网络。示例:按 F-得分(区域面积指标)对结果进行排序红色分析聚焦监督,并将最佳结果与参数组合(0% 亮度、10% 缩放、20 时期数)和产生此结果的训练神经网络一起应用于当前工具。
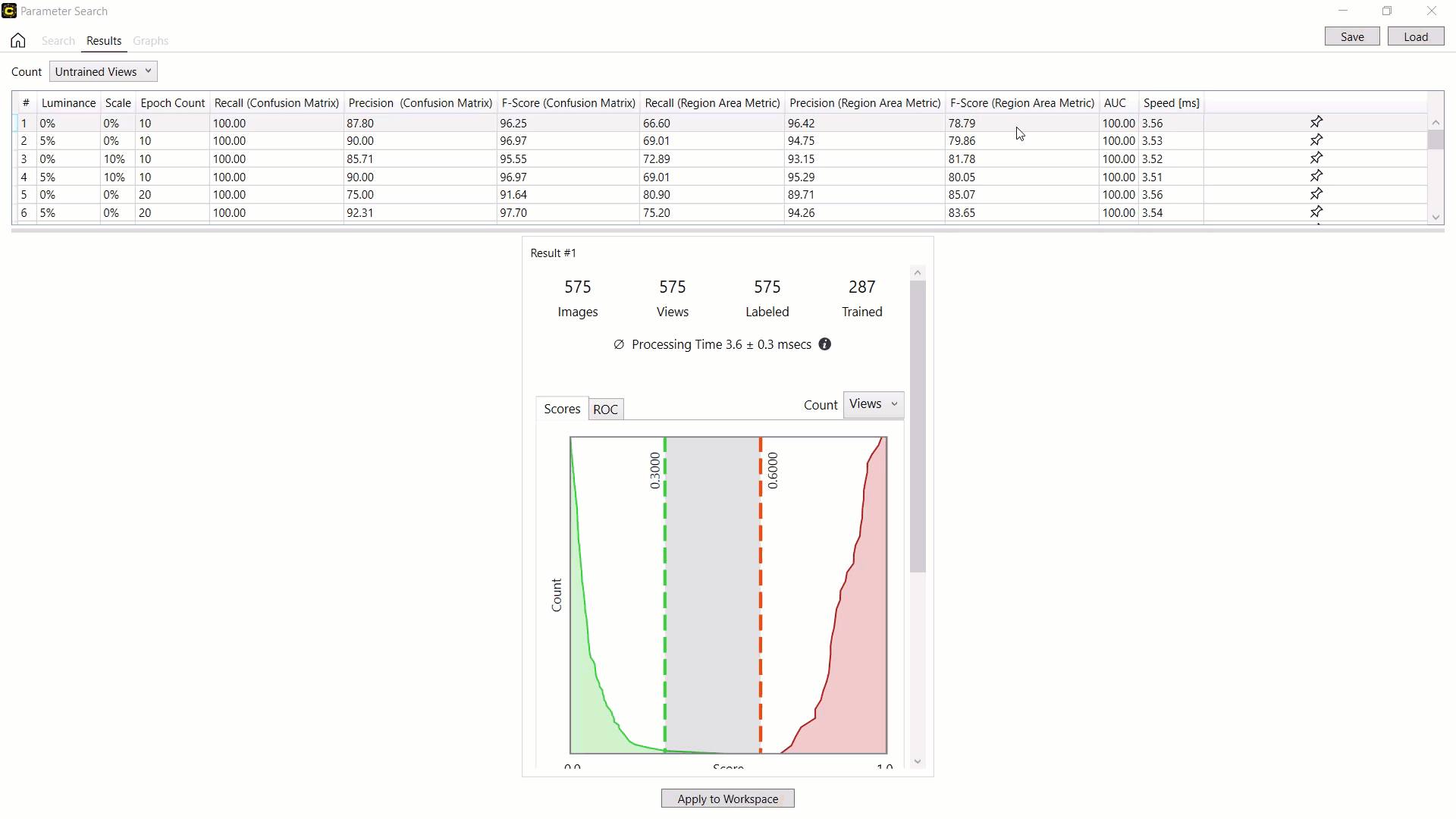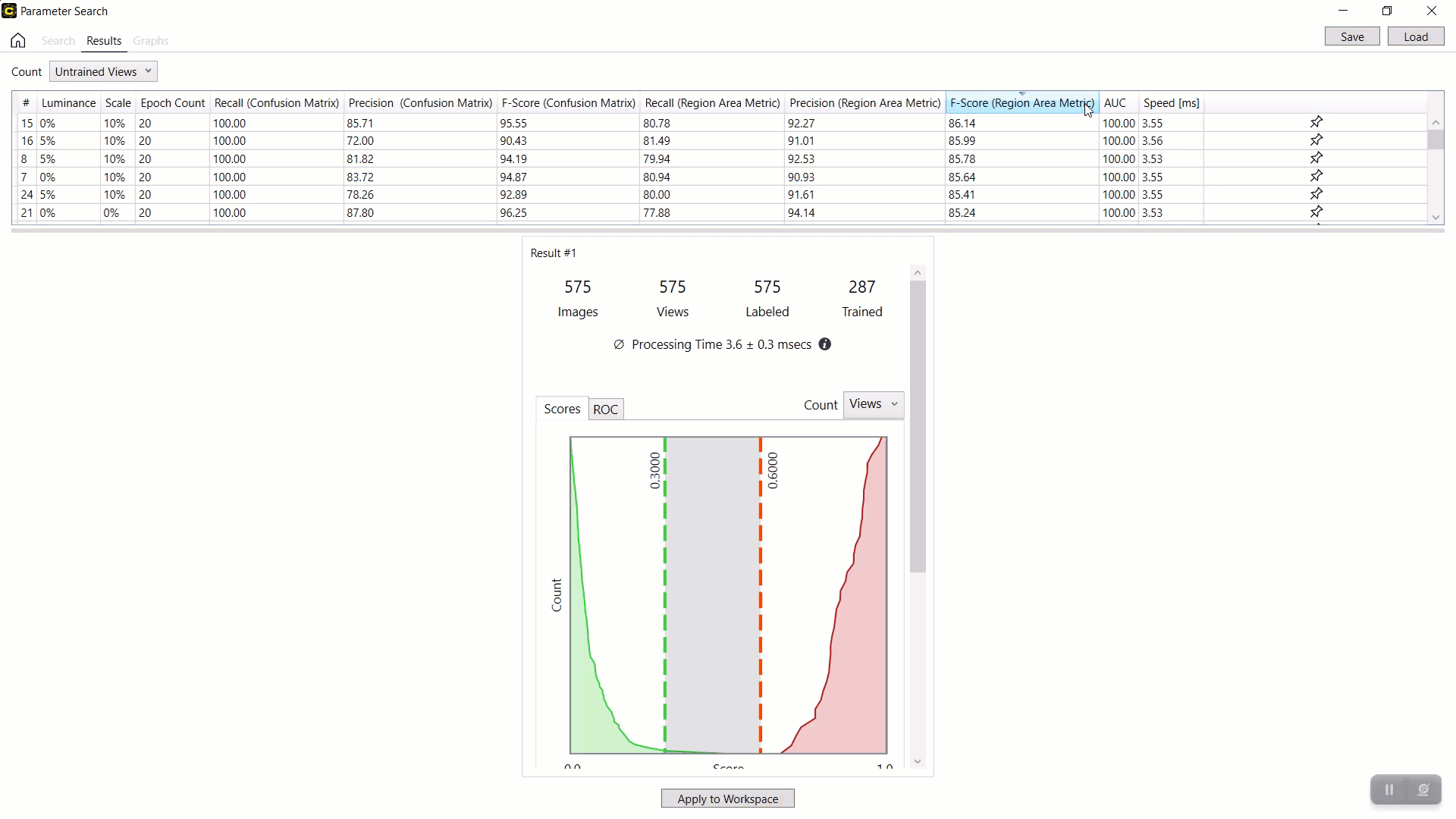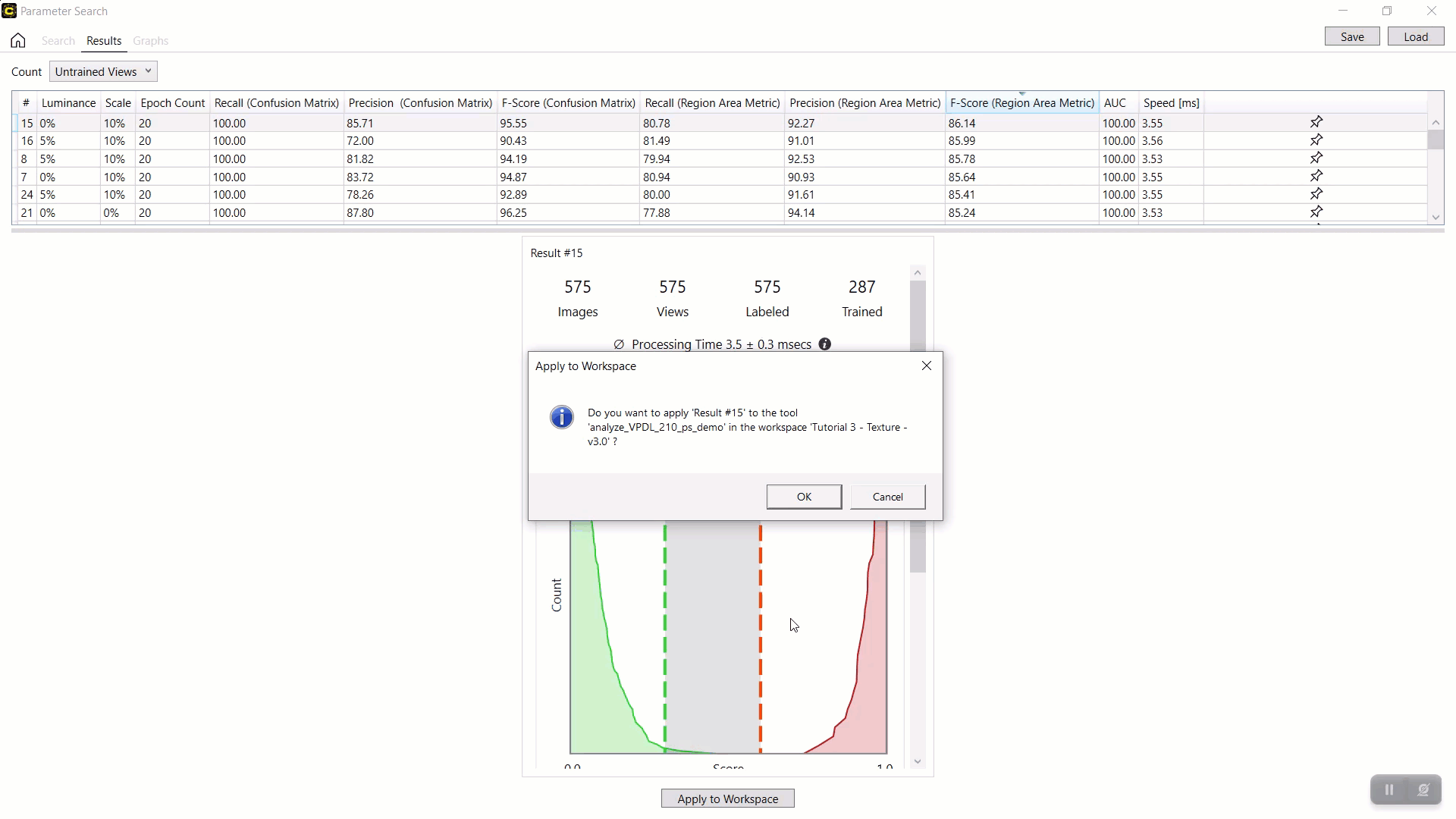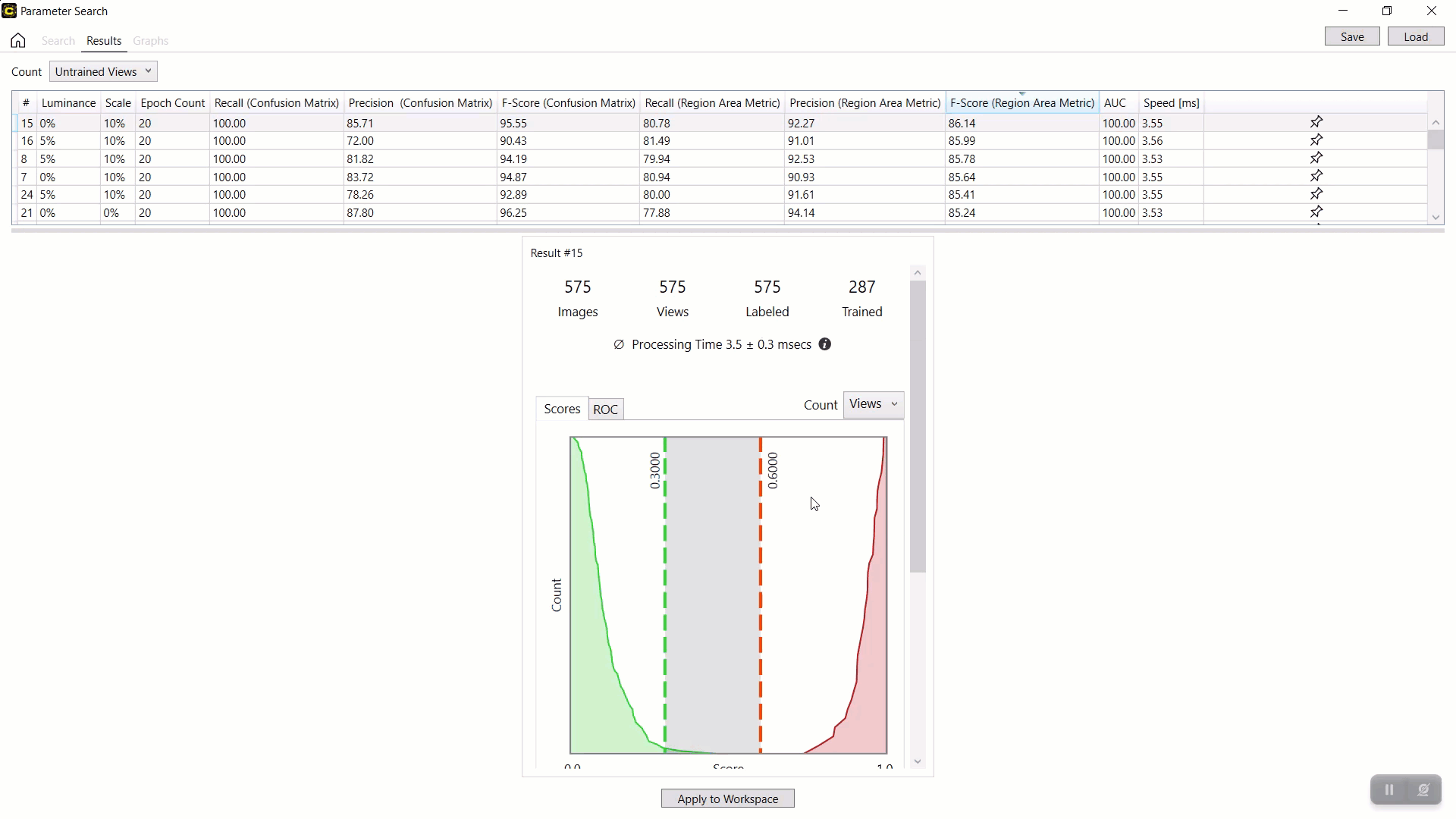
示例:启动VisionPro Deep Learning,加载工作区和工具,并处理工具以查看应用结果和参数组合。
-
单击保存以将搜索配置和搜索结果导出为参数搜索数据 XML 文件。单击加载将先前配置和保存的参数搜索数据 XML 文件导入到结果页面。它可以用作新搜索的基础。
-
请注意,搜索结果表与参数搜索数据 XML 文件一起保存,而经过训练的网络不与它一起保存。
-
-
如果您在开始搜索之前在搜索页面中启用了保存工具复选框,则包含搜索结果的工具将在搜索后保存。每个保存的工具保存与测试的每组参数值相对应的经过训练的神经网络模型。
-
例如,如果您有 10 组参数(结果表中有 10 行),则 10 个工具将作为 10 个文件保存到包含参数搜索数据 XML 文件的目录中。
-
探索图形
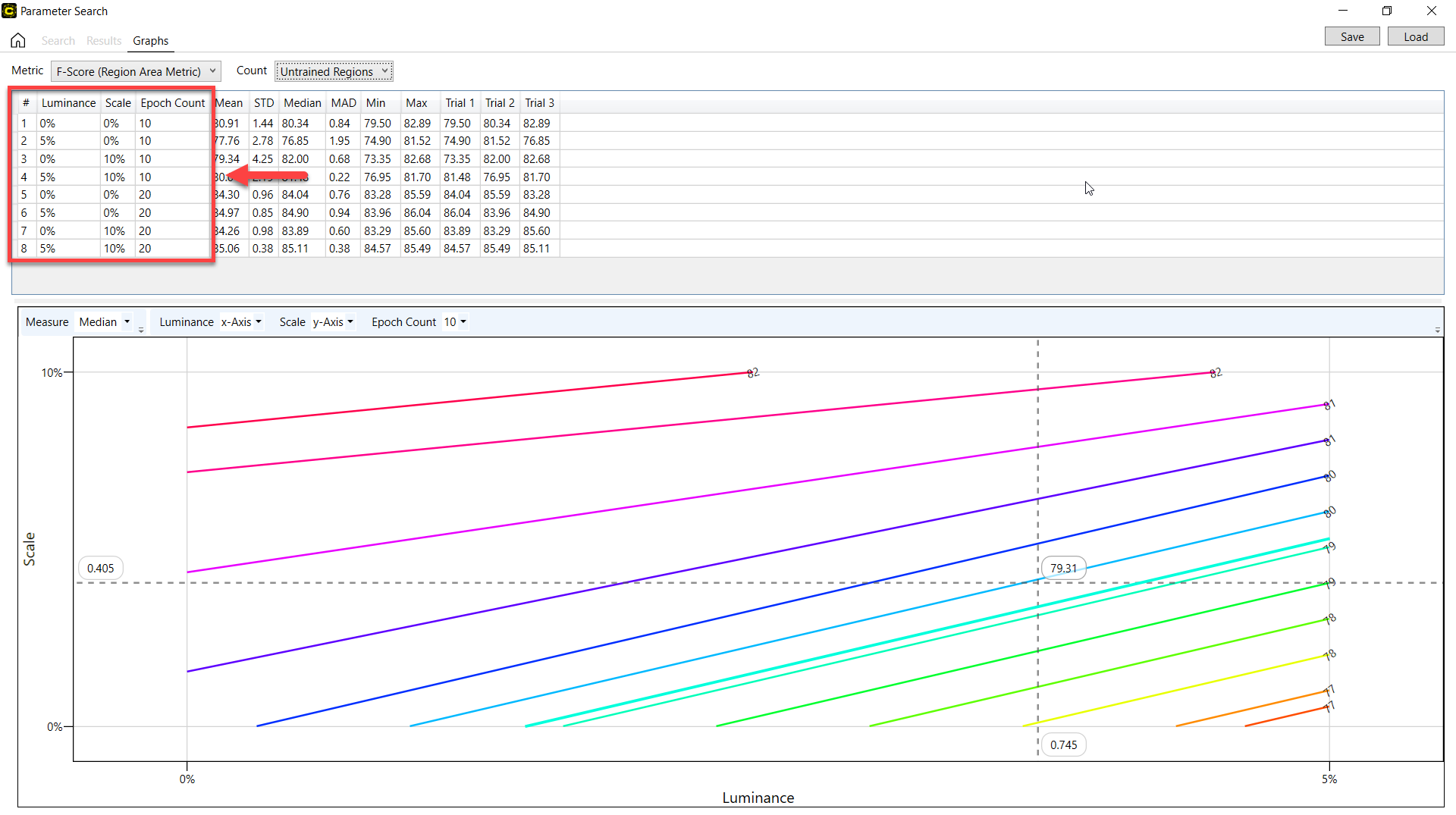
在图形页面中,搜索结果以结果表的形式显示,这与结果页面中的有些不同。该表描述了相同的结果,但这些结果是使用在所有搜索试验中计算出的一些统计度量值提供的。如果“搜索中的试验”页面设置为 1 以上,各列将在所有试验的“指标”下拉列表中显示所选指标的最小值、最大值、均值、标准偏差、中值、中值绝对偏差(如果为参数提供了这些值的话)。例如,假定提供以下搜索配置:
-
工具:红色分析聚焦监督
-
参数集:亮度、缩放、时期数
-
参数范围
-
亮度:0%, 5%
-
缩放:0%, 10%
-
时期数:10, 20
-
-
试验:3
如果结果表第一行的亮度、缩放、时期数值为 {Luminance:0%, Scale 10%, Epoch Count:10},并且如果在指标下拉列表中将性能指标设置为混淆矩阵的 F-得分,则在亮度为 0%、缩放为 10% 且时期数为 10 的第一个低点时,结果表将显示 3 次试验的混淆矩阵 F-得分的最小值、最大值、均值、标准偏差、中位数、中位数绝对偏差。有关混淆矩阵的 F-得分的详细信息,请参见红色分析工具 – 统计 – 混淆矩阵。
|
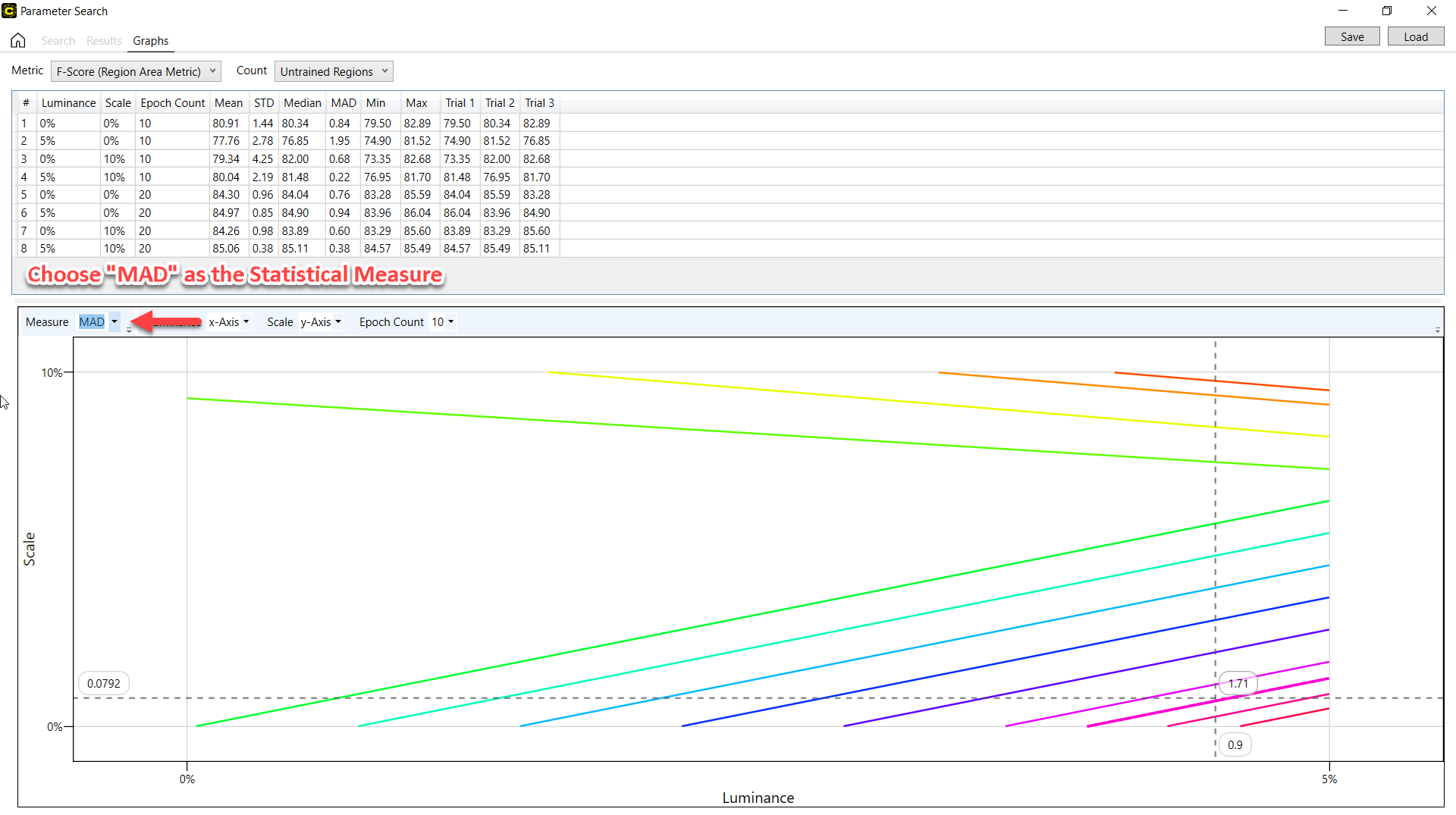
除此之外,还给出了描述 3 个或更多变量(维度)并描述搜索结果的 2D 轮廓图。特别是,这些图表根据所有试验的统计搜索结果说明了所选参数之间的关系。
要在图形上绘制搜索结果,首先要根据搜索中使用的参数设置图形的 x 轴和 y 轴。使用每个参数的下拉列表,分别将所需参数设置为 x 轴和 y 轴。
设置 2 个轴后,您就可以查看性能指标的值如何随 2 个轴的值变化。图形上绘制的数值基本上是在您滚动指标下拉列表时出现的每个性能指标的值。另外,在度量下拉列表中,您需要选择一个统计度量,该度量是针对所选指标的所有试验计算得出的。度量下拉列表中支持的度量列表如下所示:
-
均值:指标在所有搜索试验中的均值
-
标准偏差:指标在所有搜索试验中的标准偏差
-
中位数绝对偏差:指标在所有搜索试验中的中位数绝对偏差
-
中位数:指标在所有搜索试验中的中位数
|
例如,如果您将亮度设置为 x 轴,将缩放设置为 y 轴,在指标中选择 F-得分,在度量中选择中位数绝对偏差,则所有试验的 F-得分的中位数绝对偏差值将按照亮度(x 轴)和缩放(y 轴)值的变化绘制在图形上
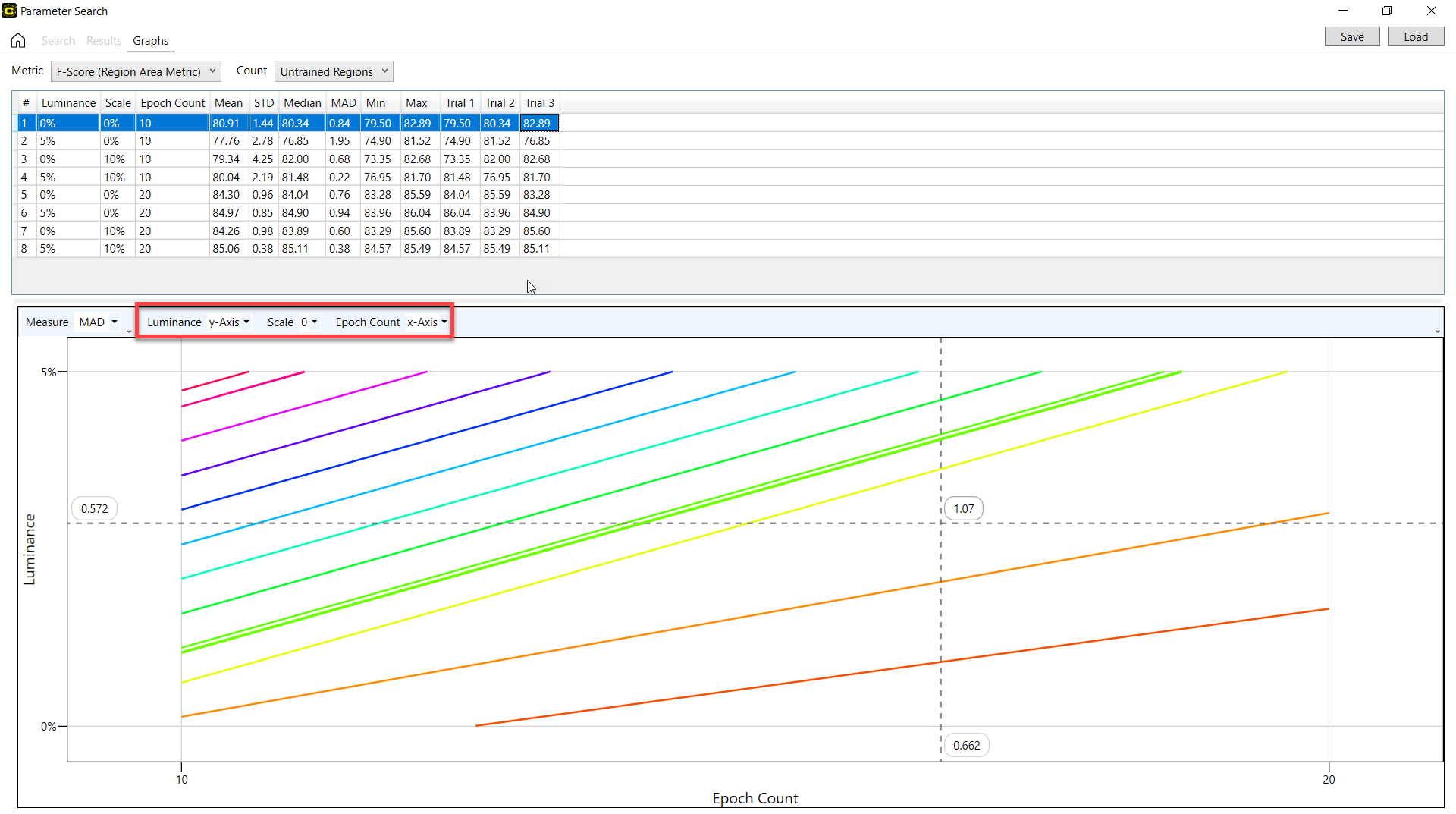
如果有 3 个或更多参数,x 轴和 y 轴的参数可以在它们之间互换。通过为每个参数的下拉列表选择特定值,也可以将 x 轴和 y 轴以外的参数值投影到图形上。
|
步骤
-
在指标下拉列表中选择 F-得分,这将在下方显示 F-得分的结果表。列显示参数值以及所有试验的 F-得分的均值、标准偏差、中值、中值绝对偏差、最小值和最大值(如果提供参数的这些值的话)。
-
对于红色分析工具,如果您在指标下拉列表中选择了混淆矩阵指标,则可以应用计数下拉列表(视图、未训练视图、区域、未训练区域)来按每个方面投影图形。有关每个选项的详细信息,请参见红色分析工具 – 统计 – 混淆矩阵。
-
对于蓝色定位/读取工具,如果您在指标下拉列表中选择精度、召回和 F-得分,则可以应用计数下拉列表(特征,模型)来投影特征的精度、召回、F-得分或图形中模型的精度、召回、F-得分。有关详细信息,请参见蓝色定位工具 - 统计和蓝色读取工具 – 统计。
-
-
在度量下拉列表中提供度量(均值、标准偏差、中值或中值绝对偏差),并设置 x 轴和 y 轴的参数。
- 如果您之前在“搜索”页面的试验栏中设置了 1 个以上的试验,则会有许多列对应于每个试验的 F-得分(试验 1、试验 2、试验 3、...、试验 N)。为指标选择的度量是针对所有试验而计算出的。
- 请注意,仅使用 1 次试验进行测试时,将不会返回标准偏差、中位数绝对偏差、最小值或最大值的结果。
-
在每个下拉列表中设置 x 轴和 y 轴以外的参数值。然后,相应的轮廓图将显示出来。
-
如果您已完成对结果表和图形的调查,并找到一组最佳参数值,则可以返回结果页面,选择描述结果表中找到的最佳集合的行,然后单击应用到工作区,在加载的工作区中应用选定的集合和经过训练的工具(神经网络模型)。当前加载的工作空间中的工具参数值和工具本身将替换为结果表中选定行中的参数值。