蓝色定位工具 - 统计
蓝色定位的数据库概述中有 2 个表,每个表显示的结果不同。上面的一个表显示图像中每个特征的结果指标,下面的另一个表显示图像中每个模型的结果指标。在这里,模型代表节点和布局模型之一,而不是蓝色定位的神经网络模型。
“标记模型”是由用户在视图上创建(标注)的模型。在处理步骤中,蓝色定位使用它来判断是否在视图中找到了此模型。因此,“找到的模型”是经过训练的蓝色定位在视图上找到的模型。
如果在大致相同的位置存在标注模型并且该找到的模型具有接近相应标注特征的特征,则认为找到的模型是正确匹配(正确标注的模型)。模型的精度、召回、F 得分都是在这个基础上计算出来的,如果一个视图中有多个模型,所有模型指标都是由每个模型分别计算的。
注意:另请参阅蓝色读取工具 – 统计主题,因为蓝色定位和蓝色读取工具都使用相同的统计方法来衡量工具的结果。
特征指标
| 表 | 指标 | 说明 |
|---|---|---|
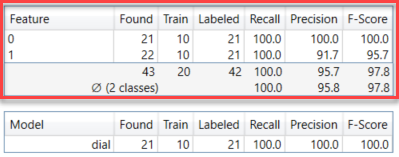
|
特征 |
特征名称 |
|
已找到 |
说明在所有视图中作为处理结果找到了该特征类的多少特征对象。 | |
|
训练 |
说明训练集中包含(标注)此特征类的多少特征对象。 | |
| 已标注 | 说明在所有视图中包含(标注)了此特征类的多少特征对象。 | |
|
召回 |
工具找到标注特征对象的可能性。召回是神经网络在所需特征实际存在的地方找到特征的能力。它表示为正确标记的特征的数量除以标注特征的数量的结果。高召回分数可能意味着找到了所有标注特征。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参见假阳性和假阴性结果。 | |
|
精度 |
工具找到已标注特征的精确程度。精度是神经网络正确定位特征的能力。它表示为正确标记的特征除以已找到特征总数的结果。在理想情况下,高精度意味着所有已找到特征都存在于图像中。但是高精度并没有考虑到所有未找到的特征,所以仍可能是 II 类错误,即有更多未被检测到的特征。有关详细信息,请参见假阳性和假阴性结果。 | |
|
F-得分 |
精度和召回的调和平均值。 |
模型指标
| 表 | 指标 | 说明 |
|---|---|---|
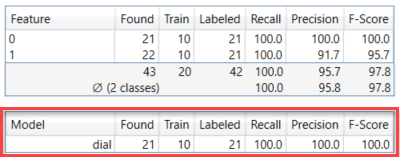
|
模型 |
模型名称。 |
|
已找到 |
说明在所有视图中作为处理结果找到了多少模型。 | |
|
训练 |
说明训练集中包含多少标注模型。 | |
|
已标注 |
说明在所有视图中有多少标注模型。 | |
|
召回 |
工具找到标注模型的可能性。召回是神经网络在所需模型实际存在的地方找到模型的能力。它表示为正确标记的模型的数量除以标注模型的数量的结果。高召回分数可能意味着找到了所有标注模型。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参见假阳性和假阴性结果。 |
|
|
精度 |
工具找到已标注模型的精确程度。精度是神经网络正确定位模型的能力。它表示为正确标记的模型除以已找到模型总数的结果。在理想情况下,高精度意味着所有已找到模型都存在于图像中。但是高精度并没有考虑到许多未找到的模型,所以仍可能是 II 类错误,即有更多未被检测到的模型。有关详细信息,请参见假阳性和假阴性结果。 | |
|
F-得分 |
精度和召回的调和平均值。 |
注意:
-
精度和召回在更改阈值参数时会发生变化,因为找到的特征数量不一定是常数。
阈值 召回
精度
降低阈值 增加
减少
提高阈值 减少
增加 - 如果要平衡的假阳性 (FP) 和假阴性 (FN) 结果,则应优化 F-得分(总体和平均值)。
- 如果您有一个模型可以滤除误报,则低精度分数的问题不大。