蓝色读取工具 – 统计
与其他工具一样,蓝色读取会显示所有未用于训练的已标注图像的统计信息。
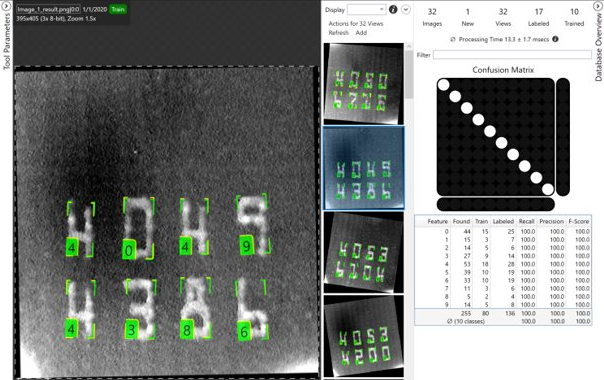
与蓝色读取工具一同显示的混淆矩阵是召回和精度得分的图形表示。
|
|
|
|
性能良好 |
性能不佳 |
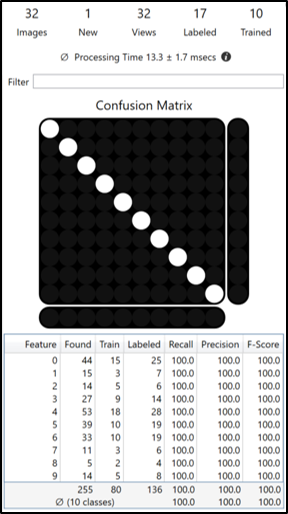
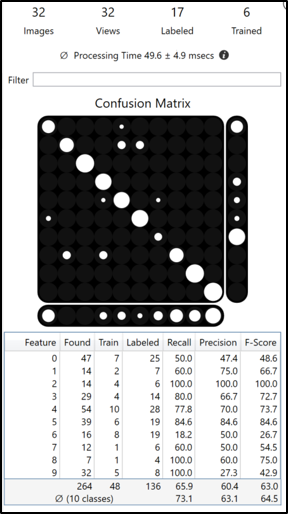
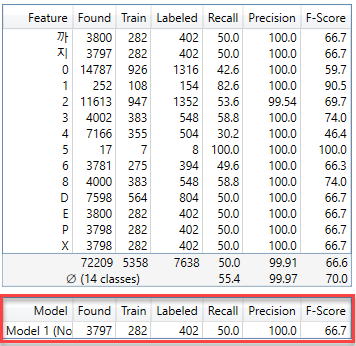
蓝色读取的数据库概述中有 2 个表,每个表显示的结果不同。上面的一个表显示图像中每个特征的结果指标,下面的另一个表显示图像中每个模型的结果指标。在这里,模型代表节点、字符串和正则表达式模型之一,而不是蓝色读取的神经网络模型。
“标记模型”是由用户在视图上创建(标注)的模型。在处理步骤中,蓝色读取使用它来判断是否在视图中找到了此模型。因此,“找到的模型”是经过训练的蓝色读取在视图上找到的模型。
如果在大致相同的位置存在标注模型并且该找到的模型具有接近相应标注特征的特征,则认为找到的模型是正确匹配(正确标注的模型)。模型的精度、召回、F 得分都是在这个基础上计算出来的,如果一个视图中有多个模型,所有模型指标都是由每个模型分别计算的。
特征指标
| 表 | 指标 | 说明 |
|---|---|---|
|
特征 |
特征名称 |
|
已找到 |
说明在所有视图中作为处理结果找到了该特征类的多少特征对象。 | |
|
训练 |
说明训练集中包含(标注)此特征类的多少特征对象。 | |
| 已标注 | 说明在所有视图中包含(标注)了此特征类的多少特征对象。 | |
|
召回 |
工具找到标注特征对象的可能性。召回是神经网络在所需特征实际存在的地方找到特征的能力。它表示为正确标记的特征的数量除以标注特征的数量的结果。高召回分数可能意味着找到了所有标注特征。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参见假阳性和假阴性结果。 | |
|
精度 |
工具找到已标注特征的精确程度。精度是神经网络正确定位特征的能力。它表示为正确标记的特征除以已找到特征总数的结果。在理想情况下,高精度意味着所有已找到特征都存在于图像中。但是高精度并没有考虑到所有未找到的特征,所以仍可能是 II 类错误,即有更多未被检测到的特征。有关详细信息,请参见假阳性和假阴性结果。 | |
|
F-得分 |
精度和召回的调和平均值。 |
模型指标
| 表 | 指标 | 说明 |
|---|---|---|
|
模型 |
模型名称。 |
|
已找到 |
说明在所有视图中作为处理结果找到了多少模型。 | |
|
训练 |
说明训练集中包含多少标注模型。 | |
| 已标注 | 说明在所有视图中有多少标注模型。 | |
|
召回 |
工具找到标注模型的可能性。召回是神经网络在所需模型实际存在的地方找到模型的能力。它表示为正确标记的模型的数量除以标注模型的数量的结果。高召回分数可能意味着找到了所有标注模型。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参见假阳性和假阴性结果。 | |
|
精度 |
工具找到已标注模型的精确程度。精度是神经网络正确定位模型的能力。它表示为正确标记的模型除以已找到模型总数的结果。在理想情况下,高精度意味着所有已找到模型都存在于图像中。但是高精度并没有考虑到许多未找到的模型,所以仍可能是 II 类错误,即有更多未被检测到的模型。有关详细信息,请参见假阳性和假阴性结果。 | |
|
F-得分 |
精度和召回的调和平均值。 |
特征的召回、精度和 F 得分的详细说明
蓝色读取工具对召回、精度和 F-得分的解释如下:
-
召回:未在工具集中且被工具正确识别的标注特征的百分比。
例如,字符“A”的召回分数为 90% 意味着神经网络在测试数据中捕获了 90% 所有出现的“A”。有关测试数据的详细信息,请参阅统计信息。



标注的图像
召回结果

-
精度:检测到的特征不在训练集中且与标准特征正确匹配的百分比。
例如,字符“A”的精度分数为 90% 意味着神经网络在给定测试数据的情况下有 90% 的机会正确识将“A”与所有其他字符特征区分开来。有关测试数据的详细信息,请参阅统计信息。


标注的图像
精度结果

- F-得分:精度和召回分数之间的调和平均数。
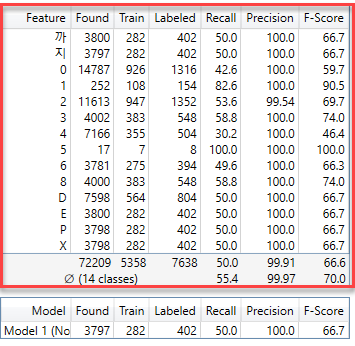
如有可能,使用模型可能有助于筛选掉虚假匹配。使用模型时,精度得分低可能问题不大。
|
|
|
|
无模型 |
已在使用模型 |

