Feature 샘플링
트레이닝![]() 트레이닝이란 도구, 즉 신경망 네트워크가 사용자가 작성한 라벨에 기반하여 Feature(픽셀)를 학습하는 과정입니다. 예를 들어, 도구는 사용자가 표시한 결함/정상 라벨에 기반하여 각 이미지의 결함/정상 픽셀을 학습합니다. 도구를 트레이닝하는 목적은 새로운 이미지가 주어졌을 때 이미지에 결함이 있는지 여부를 정확하게 검사할 수 있도록 충분히 학습하기 위한 것입니다. 트레이닝에서는 가능한 변동을 트레이닝 세트에 모두 포함하고 이미지에 정확한 라벨을 지정하는 것이 매우 중요합니다. 트레이닝 시간은 응용 프로그램, 도구 설정, 네트워크 트레이닝에 이용하는 PC의 GPU에 따라 달라집니다. 중에는 Blue 위치, Blue 읽기 및 레거시 모드 도구들이 특별한 기법을 이용해, 네트워크에 추가적인 정보를 기여할 가능성이 크다고 판단된 이미지의 부분을 더 높은 비율로 샘플링합니다. 이미지 샘플링은 전체 이미지를 대상으로 하지만 레거시 모드 도구는 동일한 방법으로 샘플링하지 않습니다.
트레이닝이란 도구, 즉 신경망 네트워크가 사용자가 작성한 라벨에 기반하여 Feature(픽셀)를 학습하는 과정입니다. 예를 들어, 도구는 사용자가 표시한 결함/정상 라벨에 기반하여 각 이미지의 결함/정상 픽셀을 학습합니다. 도구를 트레이닝하는 목적은 새로운 이미지가 주어졌을 때 이미지에 결함이 있는지 여부를 정확하게 검사할 수 있도록 충분히 학습하기 위한 것입니다. 트레이닝에서는 가능한 변동을 트레이닝 세트에 모두 포함하고 이미지에 정확한 라벨을 지정하는 것이 매우 중요합니다. 트레이닝 시간은 응용 프로그램, 도구 설정, 네트워크 트레이닝에 이용하는 PC의 GPU에 따라 달라집니다. 중에는 Blue 위치, Blue 읽기 및 레거시 모드 도구들이 특별한 기법을 이용해, 네트워크에 추가적인 정보를 기여할 가능성이 크다고 판단된 이미지의 부분을 더 높은 비율로 샘플링합니다. 이미지 샘플링은 전체 이미지를 대상으로 하지만 레거시 모드 도구는 동일한 방법으로 샘플링하지 않습니다.
샘플 영역 주위의 정보 및 context 정보를 모두 이용해 네트워크 트레이닝을 수행하므로, 도구는 이미지의 가장자리에서 수집된 샘플에 큰 영향을 받을 수 있습니다. 이미지 내의 뷰![]() 이미지의 뷰는 이미지 내의 픽셀 영역을 말합니다. 도구 프로세싱은 뷰 내의 픽셀에 제한됩니다. 사용자는 뷰를 수작업으로 지정할 수도 있고, 상위 도구의 결과를 이용해 뷰를 생성할 수도 있습니다.를 이용할 경우, 뷰의 가장자리에서 수집된 샘플에 대한 context 정보는, 뷰 외부의 픽셀을 context 데이터로 이용할 것입니다.
이미지의 뷰는 이미지 내의 픽셀 영역을 말합니다. 도구 프로세싱은 뷰 내의 픽셀에 제한됩니다. 사용자는 뷰를 수작업으로 지정할 수도 있고, 상위 도구의 결과를 이용해 뷰를 생성할 수도 있습니다.를 이용할 경우, 뷰의 가장자리에서 수집된 샘플에 대한 context 정보는, 뷰 외부의 픽셀을 context 데이터로 이용할 것입니다.
|
|
|
|
|
1 |
||
|
2 |
Sample Region(샘플 영역) |
|
|
3 |
Context Region(Context 영역) |
|
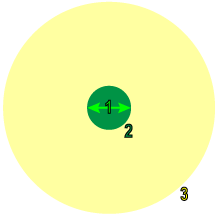

샘플이 이미지 자체의 가장자리에 있다면, 도구는 context로 이용할 합성 픽셀을 생성합니다. 사용자는 경계 유형 및 컬러 매개변수를 이용함으로써 마스크, 경계, 샘플 컬러 채널을 이용해 구체적인 방법을 제어할 수 있습니다.
마스크를 사용하면, 마스킹 모드 매개변수 설정에 따라, 마스크 프로세싱된 영역이 context로 프로세싱되는 경우라도, 이미지의 일부를 명시적으로 제외할 수 있습니다.
마지막으로, 컬러 이미지(또는 다수의 평면 또는 채널이 있는 이미지)를 이용하는 경우, 어떤 채널을 샘플링할지 명시적으로 지정할 수 있습니다. 다수 채널을 사용하는 것은 트레이닝 및 프로세싱 시간에 큰 영향을 미치지 않지만, 컬러가 중요한 정보를 제공하는 경우 도구의 정확도를 높이는 데 도움이 됩니다.
런타임 시 Feature 샘플링
런타임에서 각 input 이미지는 철저하게 샘플링되며, 개별 샘플은 트레이닝된 네트워크에 의해 프로세싱됩니다. 트레이닝에 이용된 Feature![]() Feature는 이미지에서 시각적으로 구별할 수 있는 영역입니다. Feature는 대개 응용 프로그램의 관심 대상(결함, 개체, 개체의 특정 구성 요소)을 나타냅니다. 크기가 런타임에도 이용됩니다(트레이닝된 네트워크가 트레이닝 때 이용한 입력과 일관된 입력을 프로세싱하도록 보장).
Feature는 이미지에서 시각적으로 구별할 수 있는 영역입니다. Feature는 대개 응용 프로그램의 관심 대상(결함, 개체, 개체의 특정 구성 요소)을 나타냅니다. 크기가 런타임에도 이용됩니다(트레이닝된 네트워크가 트레이닝 때 이용한 입력과 일관된 입력을 프로세싱하도록 보장).
샘플링 밀도![]() 이미지 내에서 샘플 간에 샘플링 지점이 이동하는 양을 말하며, Feature 크기를 기준으로 표현됩니다. Feature 크기가 100이고 샘플링 밀도가 1이라면, 샘플링 위치는 샘플 간에 100픽셀 이동합니다. 샘플링 밀도가 4이면, 샘플 위치가 25픽셀씩 이동합니다.가 자동으로 결정되는 트레이닝과 달리, 런타임의 샘플링 밀도는 모든 Deep Learning 도구에서 사용자가 제어할 수 있습니다. 샘플링 밀도는 인접 샘플 간의 중복 정도를 결정합니다. 샘플링 밀도 비율이 1이면, 다음 샘플의 샘플링 위치가 Feature 크기만큼 증가한다는 뜻입니다. 대부분의 도구는 샘플링 밀도 비율의 기본값이 3이며, 이는 샘플링 위치가 Feature의 1/3만큼 증가하게 된다는 뜻입니다.
이미지 내에서 샘플 간에 샘플링 지점이 이동하는 양을 말하며, Feature 크기를 기준으로 표현됩니다. Feature 크기가 100이고 샘플링 밀도가 1이라면, 샘플링 위치는 샘플 간에 100픽셀 이동합니다. 샘플링 밀도가 4이면, 샘플 위치가 25픽셀씩 이동합니다.가 자동으로 결정되는 트레이닝과 달리, 런타임의 샘플링 밀도는 모든 Deep Learning 도구에서 사용자가 제어할 수 있습니다. 샘플링 밀도는 인접 샘플 간의 중복 정도를 결정합니다. 샘플링 밀도 비율이 1이면, 다음 샘플의 샘플링 위치가 Feature 크기만큼 증가한다는 뜻입니다. 대부분의 도구는 샘플링 밀도 비율의 기본값이 3이며, 이는 샘플링 위치가 Feature의 1/3만큼 증가하게 된다는 뜻입니다.
| 샘플링 밀도 = 1(4개의 샘플) | 샘플링 밀도 = 3(4개의 샘플) |
|---|---|
|
|
|

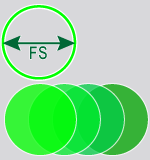
이미지 크기, Feature 크기, 샘플링 밀도 설정이 한계를 넘는 경우, 다음 오류 메시지가 표시될 수 있습니다.
"데이터베이스 샘플 'image_file.name'을(를) 프로세싱하지 못했습니다(샘플 최대 수 초과)."
이 경우, 마스크를 이용해 ROI![]() 관심 영역(ROI)은 도구가 작동하는 영역을 정의합니다. ROI는 원본 이미지의 위치, 각도, 확장 및 왜곡을 그대로 보존합니다.를 특정 영역에 국한하거나 Feature 크기 설정을 크게 해 프로세싱하는 픽셀 수를 줄이는 대안을 검토하십시오.
관심 영역(ROI)은 도구가 작동하는 영역을 정의합니다. ROI는 원본 이미지의 위치, 각도, 확장 및 왜곡을 그대로 보존합니다.를 특정 영역에 국한하거나 Feature 크기 설정을 크게 해 프로세싱하는 픽셀 수를 줄이는 대안을 검토하십시오.