결과 해석
도구 학습과 프로세싱이 끝나면, 도구 결과는 모든 뷰에서 계산됩니다. 하지만, 도구를 정확하게 평가하려면 반드시 테스트 세트에서 계산된 결과만을 검토해야 합니다.
테스트 세트: 결과 평가를 위한 이미지들
VisionPro Deep Learning의 통계적 지표들은 트레이닝된 신경망의 성과를 평가하는 데 이용됩니다. 딥러닝의 패러다임에서, 평가(evaluation)란 트레이닝이 끝난 신경망 모델을 테스트 데이터(라벨링이 되어 있지만 트레이닝에는 사용되지 않은 데이터)로 평가하는 일을 말합니다. 즉, 통계 지표들을 활용해 어떤 신경망 모델이 쓸만한 것인지 그리고 성능은 괜찮은지를 결정할 때, 이 통계 지표들은 반드시 테스트 데이터에서만 산출되어야 합니다.
신경망 모델 즉 도구(Blue 위치/읽기 또는 Green 분류 또는 Red 분석)를 트레이닝한 후에, 모델이 얼마나 잘 트레이닝되었는지 점검하려면 이 모델을 트레이닝하는 데 사용한 데이터로 모델을 테스트할 수 없음에 주의하십시오. 트레이닝 데이터는 이미 트레이닝된 모델을 평가하는 데 사용할 수 없습니다. 왜냐하면, 트레이닝 과정에서는 트레이닝 데이터가 주어졌을 때 가장 좋은 성능을 내야 하므로 모델은 이미 이 데이터에 맞춰졌기 때문입니다. 그래서 이 데이터는 생소한 그리고 이질적인 데이터가 주어졌을 때 모델이 얼마나 일반적으로 그리고 기대한대로 잘 작동하는지 알려줄 수 없습니다.
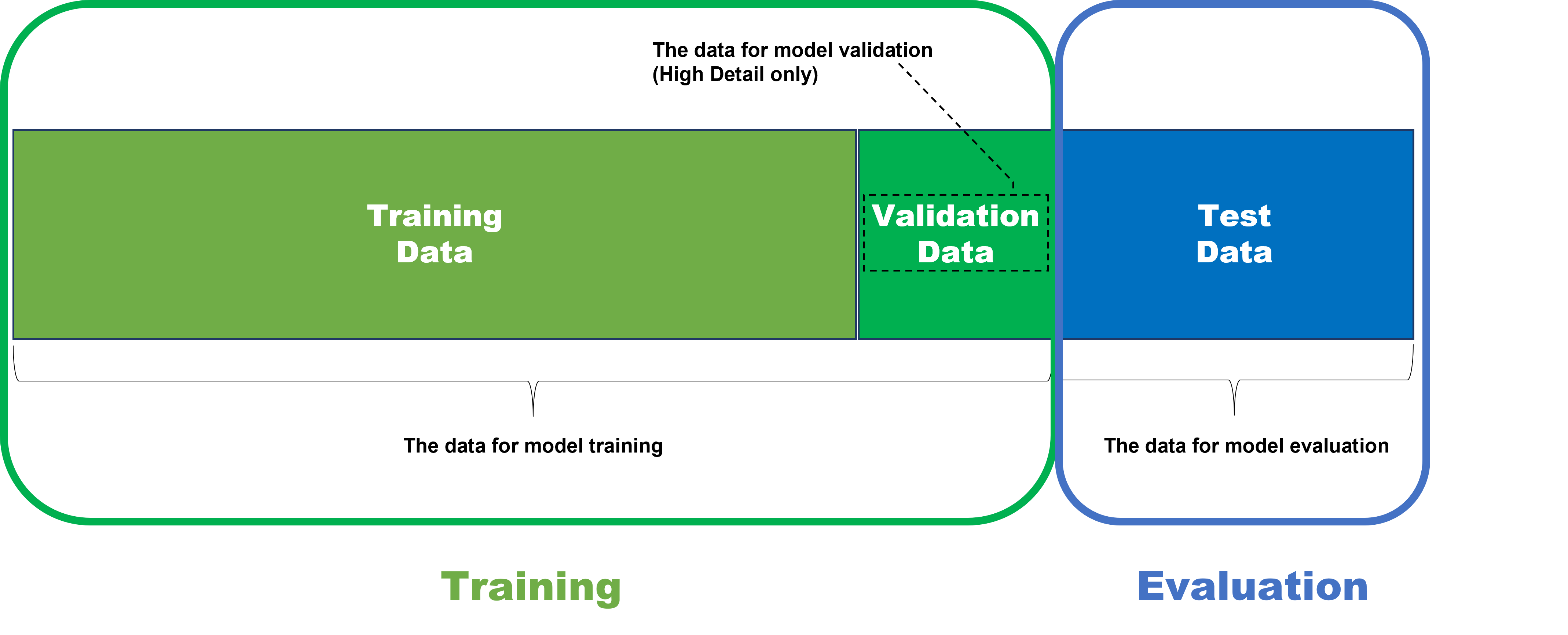
결국, 모델의 가용성과 성능을 공정하고 정확하게 테스트하려면, 모델은 트레이닝 과정을 포함하여 반드시 과거에 입력 받지 않은 데이터를 대상으로 테스트를 받아야 합니다. 이것이 바로 모델 평가를 위해 사용되는 데이터가 테스트 데이터 세트로 불리는 이유입니다.
Database Overview(데이터베이스 개요)
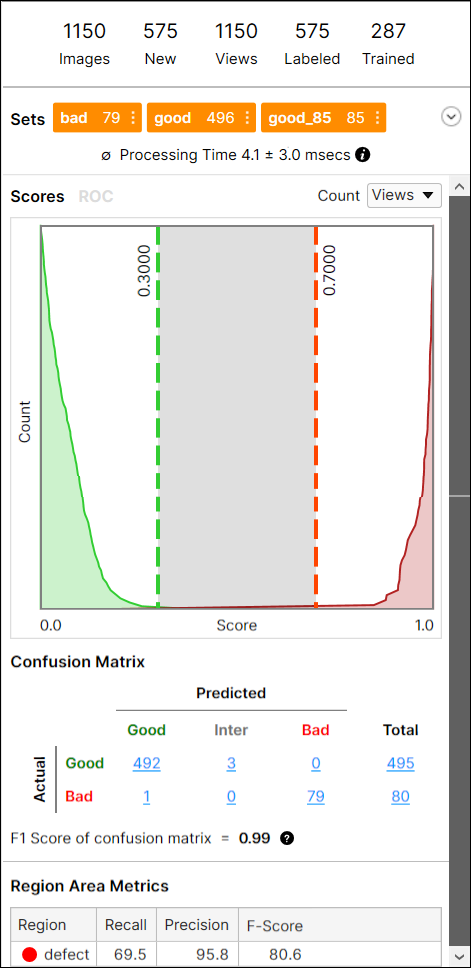
데이터베이스 개요 창을 통해, 트레이닝에 이용된 이미지 및 뷰에 대한 정보와 Cognex Deep Learning 도구들이 생성한 통계량 결과를 볼 수 있습니다. 이 창은 선택된 도구에 따라 디스플레이가 다릅니다.
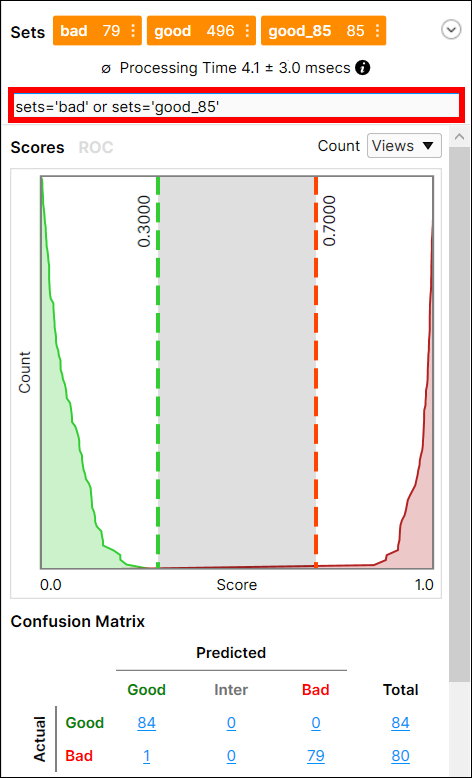
전문가 모드에서는, 필터 필드를 이용해 이미지/뷰를 분리하고 해당 이미지/뷰에 대해서만 통계 분석을 수행할 수 있습니다. 이미지/뷰의 필터링 systax에 대한 자세한 내용은 디스플레이 필터 및 필터 항목을 참조하고, 해당 필터의 자세한 사용 방법은 테스트 이미지 샘플 Set항목을 참조하십시오.
프로세싱 시간
개별 도구의 프로세싱 시간은 아래와 같이 데이터베이스 개요에 표시됩니다:
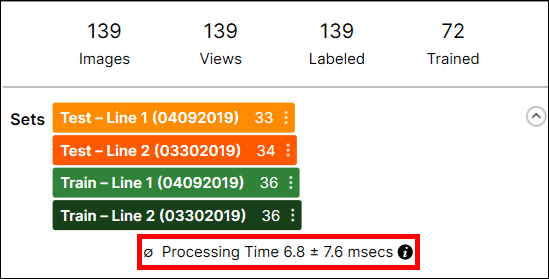
프로세싱 시간은 프로세싱 시간과 사후 프로세싱 시간이 더해진 시간입니다. 다수 도구를 포함하는 스트림의 프로세싱 시간은 VisionPro Deep Learning GUI에서 제공되지 않으며, 스트림 내에 있는 도구의 실행 시간을 합산하여 추정할 수 없습니다. 프로세싱 시간에는 도구 간에 뷰를 준비하고 전송하는 시간이 포함되기 때문입니다.
결과 지표
Red 분석 도구의 경우, 도구 트레이닝이 완료되면, 지도 모드(Red 분석 도구 Focused 지도 모드, Red 분석 도구 High Detail 모드)인지 비지도 모드(Red 분석 도구 Focused 비지도 모드)인지에 따라 결과가 그래프와 Confusion Matrix 형태로 데이터베이스 개요에 표시됩니다.
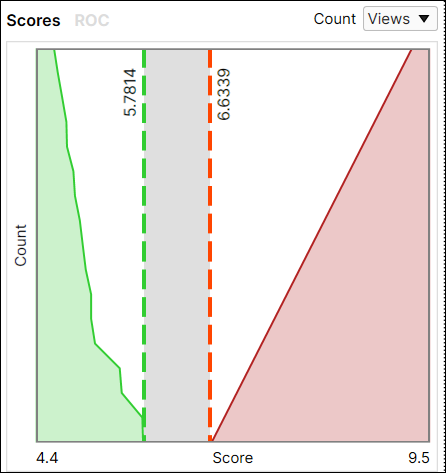
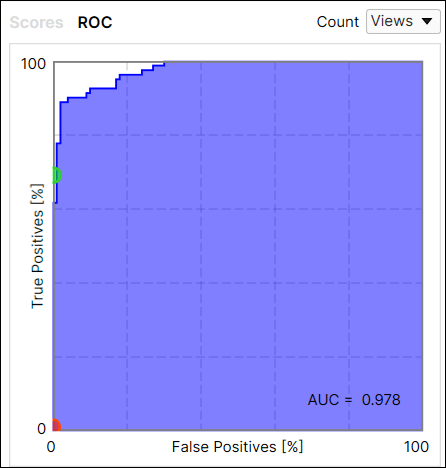
Red 분석 도구 Focused 비지도 모드 지표 결과는 다음과 같습니다:
- 점수 히스토그램
- 수신자 조작 특성(ROC) 곡선 및 곡선 아래 면적(AUC)
- Confusion Matrix (Precision, Recall, F-Score)
기본 개념: False Positives, False Negatives
통계적 결과 외에도, 이 결과에 따라 False Positive 및 False Negative 결과가 어떤 영향을 받는지도 이해해야 합니다.
이미지에서 결함을 찾아내는 이미지 검사 기계가 있다고 가정해보겠습니다. 이 기계가 어떤 이미지에서 결함을 찾아낸다면 이 이미지 검사 결과는 Positive라고 하고, 어떤 결함도 찾지 못하면 검사 결과를 Negative라고 합니다. 이 때, 검사 결과 통계치는 다음과 같이 요약될 수 있습니다:
-
False Positive (또는 제1종 오류)
-
뷰 또는 픽셀에 결함이 실제로는 없음에도 불구하고 이미지 검사기는 결함을 발견했다고 판단함.
-
-
False Negative (또는 제2종 오류)
-
뷰 또는 픽셀에 결함이 실제로는 있음에도 불구하고 이미지 검사기는 결함을 찾지 못함.
-
기본 개념: Precision, Recall, F-Score
False Positives와 False Negatives는 모든 VisionPro Deep Learning 도구들에서 쓰이는 통계적 결과값들인 Precision과 Recall로 요약되어 표현됩니다.
- Precision
- 일반적으로, 낮은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 결함을 정확하게 검출하는 데 실패하며, 따라서 많은 False Positive(제1종 오류)가 발생합니다.
- 일반적으로, 높은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 결함을 정확하게 검출하는 데 성공하지만, 만약 Recall이 낮을 경우 많은 False Negative(제2종 오류)가 발생할 가능성이 있습니다.
- Recall
- 일반적으로, 낮은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 결함을 충분히 검출하는 데 실패하며, 따라서 많은 False Negative(제2종 오류)가 발생합니다.
- 일반적으로, 높은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 결함을 충분히 검출하는 데 성공하지만, 만약 Precision이 낮을 경우 많은 False Positive(제1종 오류)가 발생할 가능성이 있습니다.
요약하면,
- Precision - 라벨 지정된 결함과 일치하는 결함을 검출한 비율.
- Recall - 도구에 의해 정확하게 식별된, 라벨 지정된 결함의 비율.
- F-Score – Recall과 Precision의 조화 평균.
거의 모든 검사 사례에서 (예외가 있을 수 있음) 이상적인 통계적 결과는 높은 Precision과 높은 Recall을 동시에 보이는 결과입니다.