결과 해석
도구 학습과 프로세싱이 끝나면, 도구 결과는 모든 뷰에서 계산됩니다. 하지만, 도구를 정확하게 평가하려면 반드시 테스트 세트에서 계산된 결과만을 검토해야 합니다.
테스트 세트: 결과 평가를 위한 이미지들
VisionPro Deep Learning의 통계적 지표들은 트레이닝된 신경망의 성과를 평가하는 데 이용됩니다. 딥러닝의 패러다임에서, 평가(evaluation)란 트레이닝이 끝난 신경망 모델을 테스트 데이터(라벨링이 되어 있지만 트레이닝에는 사용되지 않은 데이터)로 평가하는 일을 말합니다. 즉, 통계 지표들을 활용해 어떤 신경망 모델이 쓸만한 것인지 그리고 성능은 괜찮은지를 결정할 때, 이 통계 지표들은 반드시 테스트 데이터에서만 산출되어야 합니다.
신경망 모델 즉 도구(Blue 위치/읽기 또는 Green 분류 또는 Red 분석)를 트레이닝한 후에, 모델이 얼마나 잘 트레이닝되었는지 점검하려면 이 모델을 트레이닝하는 데 사용한 데이터로 모델을 테스트할 수 없음에 주의하십시오. 트레이닝 데이터는 이미 트레이닝된 모델을 평가하는 데 사용할 수 없습니다. 왜냐하면, 트레이닝 과정에서는 트레이닝 데이터가 주어졌을 때 가장 좋은 성능을 내야 하므로 모델은 이미 이 데이터에 맞춰졌기 때문입니다. 그래서 이 데이터는 생소한 그리고 이질적인 데이터가 주어졌을 때 모델이 얼마나 일반적으로 그리고 기대한대로 잘 작동하는지 알려줄 수 없습니다.
결국, 모델의 가용성과 성능을 공정하고 정확하게 테스트하려면, 모델은 트레이닝 과정을 포함하여 반드시 과거에 입력 받지 않은 데이터를 대상으로 테스트를 받아야 합니다. 이것이 바로 모델 평가를 위해 사용되는 데이터가 테스트 데이터 세트로 불리는 이유입니다.
Database Overview(데이터베이스 개요)
데이터베이스 개요 창을 통해, 트레이닝에 이용된 이미지 및 뷰에 대한 정보와 Cognex Deep Learning 도구들이 생성한 통계량 결과를 볼 수 있습니다. 이 창은 선택된 도구에 따라 디스플레이가 다릅니다.
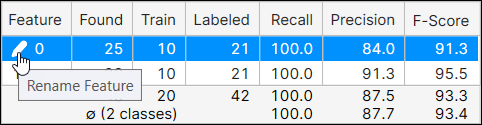
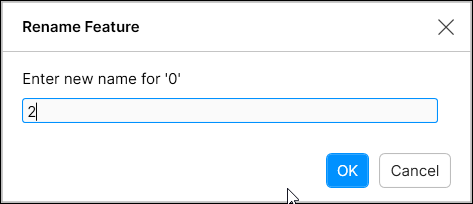
Feature의 이름을 클릭한 후 연필 아이콘을 클릭해 'feature 이름 변경' 대화 상자를 띄우면 feature 이름을 변경할 수 있습니다.
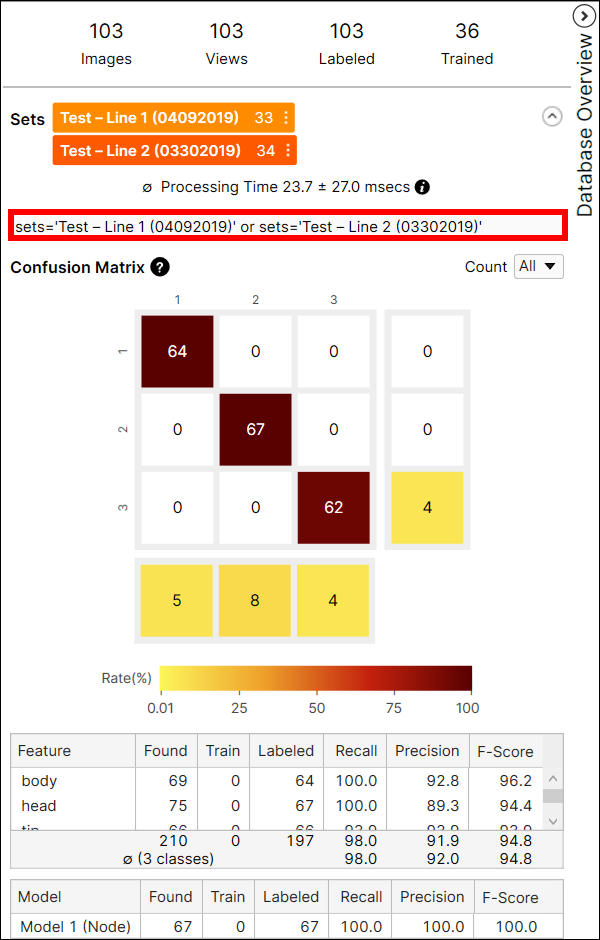
전문가 모드에서는, 필터 필드를 이용해 이미지/뷰를 분리하고 해당 이미지/뷰에 대해서만 통계 분석을 수행할 수 있습니다. 이미지/뷰의 필터링 systax에 대한 자세한 내용은 디스플레이 필터 및 필터 항목을 참조하고, 해당 필터의 자세한 사용 방법은 테스트 이미지 샘플 Set항목을 참조하십시오.
프로세싱 시간
개별 도구의 프로세싱 시간은 아래와 같이 데이터베이스 개요에 표시됩니다:
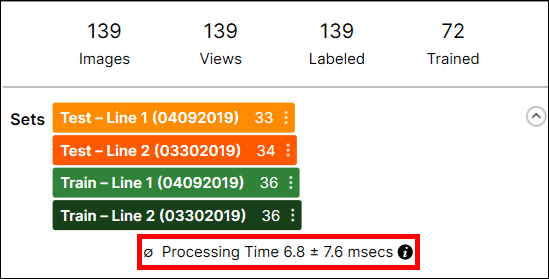
프로세싱 시간은 프로세싱 시간과 사후 프로세싱 시간이 더해진 시간입니다. 다수 도구를 포함하는 스트림의 프로세싱 시간은 VisionPro Deep Learning GUI에서 제공되지 않으며, 스트림 내에 있는 도구의 실행 시간을 합산하여 추정할 수 없습니다. 프로세싱 시간에는 도구 간에 뷰를 준비하고 전송하는 시간이 포함되기 때문입니다.
Confusion Matrix
Confusion Matrix는 ground truth와 도구의 예측을 시각적으로 표현한 것입니다. 도구에서 제공하는 Confusion Matrix는 Recall 및 Precision 점수를 표로 나타낸 것입니다. Confusion Matrix 각 행은 사용자가 라벨링한 feature 개수를 나타내며 이는 ground truth에 해당합니다. 그리고 Confusion Matrix 각 열은 도구가 예측한 feature 개수를 나타내며 이는 마킹에 해당합니다. 데이터베이스 개요에서 Confusion Matrix 각 셀을 클릭하면, 각 셀에 해당하는 뷰들이 뷰 브라우저에 표시됩니다.
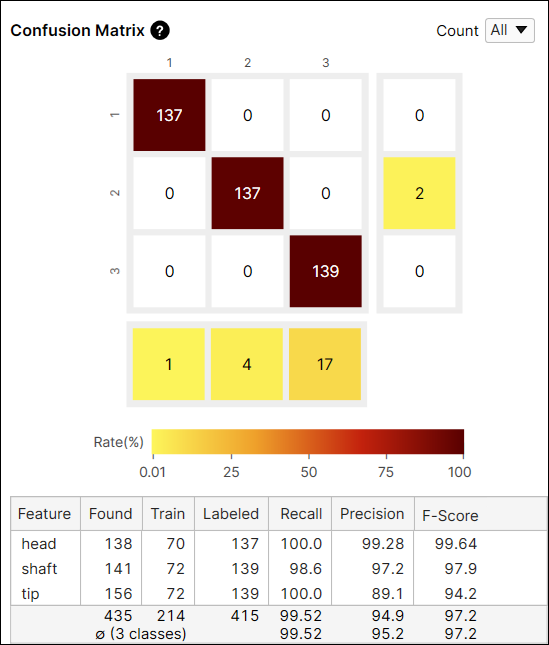
Confusion Matrix 셀 색상은 예측한 feature 개수(셀 값) / 라벨링한 feature 총 개수(행 합계)를 나타냅니다. 색이 어두울수록 높은 비율 값을, 밝을 수록 낮은 비율 값을 뜻합니다.
예를 들어, (2,2) 위치에 있는 셀은 갈색입니다. 왜냐하면 'shaft' 라벨을 가진 feature 중에서 'shaft'로 예측된 feature 개수가 127개이고, 이는 'shaft' 라벨을 가진 모든 feature의 90.7%(127/140)나 차지하기 때문입니다.
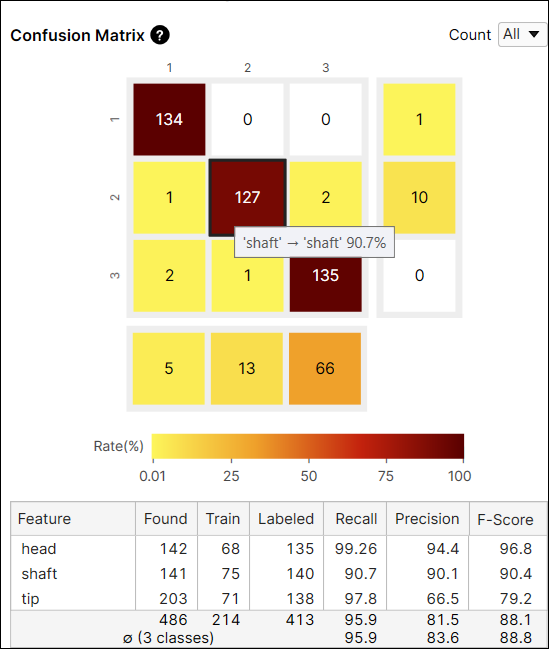
다른 예로, (2,3) 위치에 있는 셀은 노란색입니다. 왜냐하면 'shaft' 라벨을 가진 feature 중에서 'tip'로 예측된 feature 개수가 2개이기 때문입니다. 'tip'로 예측된 feature는 'shaft' 라벨을 가진 모든 feature 중에서 단 1.4%(2/140)만 차지합니다.
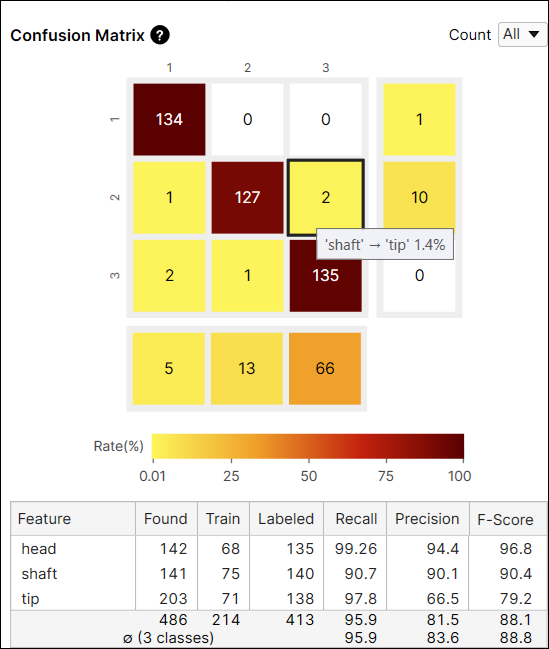
일반적으로 어두운 셀들이 Confusion Matrix 대각선 위치에 나타나는 것이 권장되는데, 이는 바람직한 결과를 얻은 것으로 여겨지기 때문입니다.
|
|
|
|
양호한 성능 |
불량한 성능 |
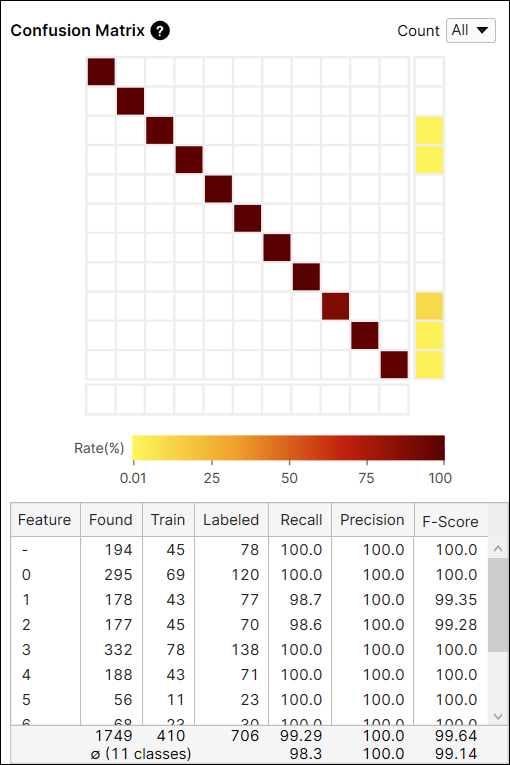
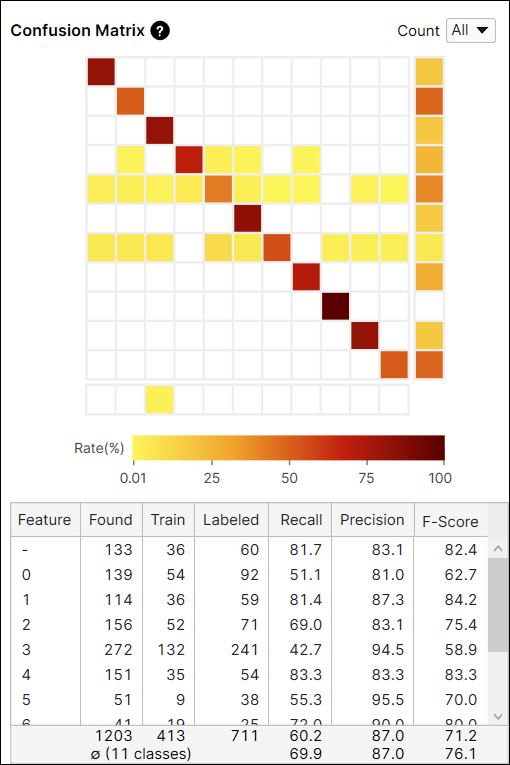
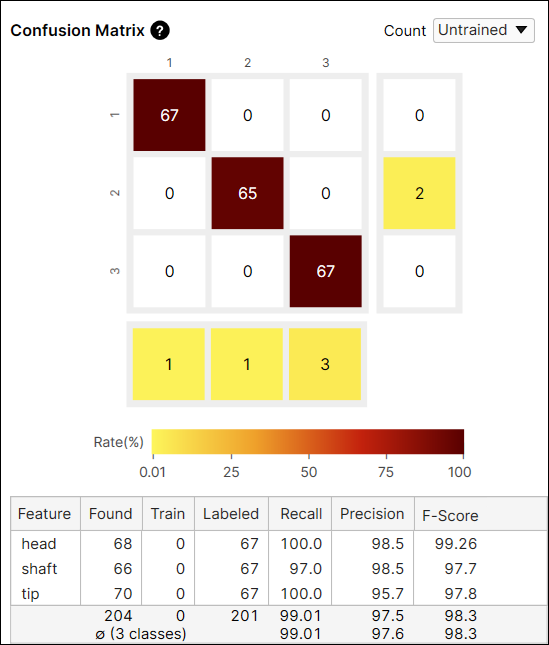
Confusion Matrix의 숫자 계산: 전체 뷰 vs 학습되지 않은 뷰
Confusion Matrix 카운트 옵션으로 모든 뷰 또는 학습 세트에 포함되지 않은 뷰(학습 되지 않은 뷰)에서만 현재 도구 결과를 확인할 수 있습니다. 학습과 테스트 이미지를 포함한 모든 뷰에 대한 결과를 표시하거나, 학습되지 않은 뷰 즉 테스트 이미지에 대한 결과를 표시할 수 있습니다.
결과 지표
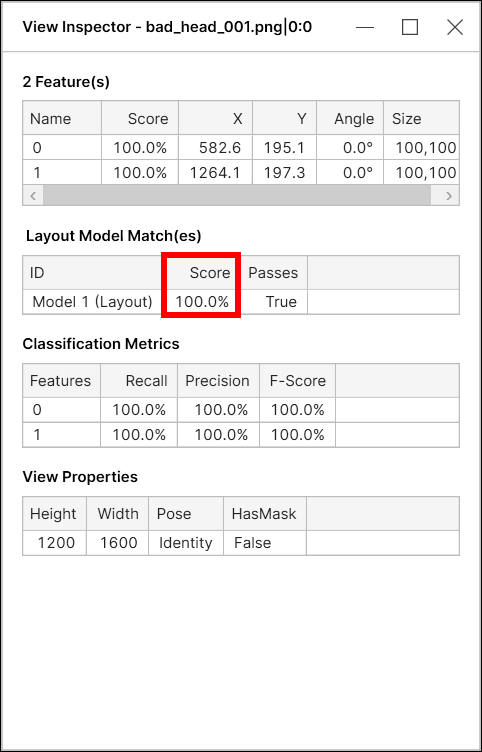
Blue 위치 도구 데이터베이스 개요에는 서로 다른 종류의 결과를 보여주는 테이블 2개가 있습니다. 위에 있는 테이블은 이미지에 있는 각 feature에 대한 결과 통계치를 보여주고, 아래 테이블은 이미지에 있는 각 모델에 대한 결과 통계치를 보여줍니다. 여기서, 모델이란 노드 모델 또는 레이아웃 모델을 의미하며 Blue 위치 도구의 신경망 모델을 의미하지 않습니다.
"라벨링된 모델"이란 사용자들이 뷰에 직접 생성(라벨링)한 모델입니다. 프로세싱 단계에서 Blue Locate은 라벨링된 모델 정보를 바탕으로 이 모델이 뷰에서 발견되는지 아닌지를 판단합니다. 따라서, "발견된 모델"이란 트레이닝을 마치고 학습이 완료된 Blue 위치 도구가 뷰에서 찾아낸 모델을 말합니다.
발견된 모델이 라벨링된 모델과 거의 비슷한 위치에서 발견되고 이 발견된 모델이 가진 feature들이 라벨링된 feature들과 같을 경우, 발견된 모델은 일치하는 모델(정확하게 마킹된 모델)이라고 불립니다. 모델 Precision, Recall, F-score는 이러한 배경에서 계산되며, 어떤 뷰에 여러 모델이 있다면 모든 통계량은 모델별로 따로 계산됩니다.
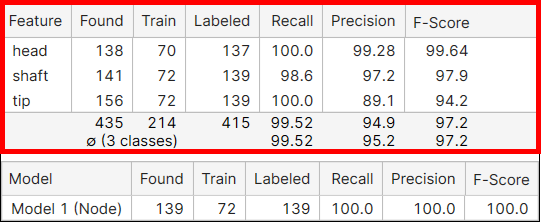
Features 통계량
| 표 | 지표 | 설명 |
|---|---|---|
|
특징 |
feature 이름. |
|
찾음 |
프로세싱 결과로 모든 뷰에서 이 feature 클래스에 속하는 feature 객체들이 발견된 개수입니다. | |
|
트레이닝 |
트레이닝 세트에 존재하는 이 feature 클래스에 속하는 feature 객체들(라벨링된 feature) 개수입니다. | |
| 라벨링 | 모든 뷰에 존재하는 이 feature 클래스에 속하는 feature 객체들(라벨링된 feature) 개수입니다. | |
|
Recall |
해당 도구가 라벨링된 feature 객체들을 찾을 가능성이 얼마나 높은가입니다. Recall은 실제로 원하는 feature가 있을 때 신경망이 이를 얼마나 빠짐없이 잘 찾아낼 수 있는지와 관련된 능력입니다. 이는 정확하게 마킹된 feature 수를 라벨 지정된(라벨링된) feature 수로 나눈 값입니다. Recall 점수가 높으면, 라벨 지정된 feature를 최대한 모두 찾게 되므로 좋습니다. 하지만 Recall은 부정확하게 발견된 것은 고려하지 않으므로, 높은 Recall이라도 제 1종 오류를 의미할 수도 있습니다. 자세한 내용은 기본 개념: False Positives, False Negatives 항목을 확인하십시오. | |
|
Precision |
얼마나 정확하게 라벨링된 feature를 찾아내는가입니다. Precision은 feature를 정확히 찾아내는 신경망의 능력입니다. 이는 정확하게 마킹된 feature 수를 발견된 전체 feature 수로 나눈 값입니다. Precision 점수가 높으면 발견된 모든 feature가 이미지에 존재함을 나타내는 것이므로 좋습니다. 하지만, 높은 Precision은 실제로 뷰에 존재하지만 발견되지는 않은 feature를 고려하지 않으므로, 검출되지 않은 feature가 훨씬 많은 상황인 제 2종 오류가 발생할 수 있습니다. 자세한 내용은 기본 개념: False Positives, False Negatives를 확인하십시오. | |
|
F-Score |
Precision과 Recall의 조화 평균입니다. |
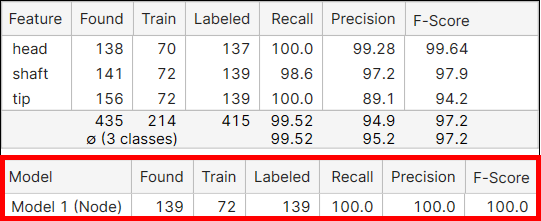
Models 통계량
| 표 | 지표 | 설명 |
|---|---|---|
|
모델 |
모델 이름입니다. |
|
찾음 |
프로세싱 결과로 모든 뷰에서 발견된 이 모델 개수입니다. | |
|
트레이닝 |
트레이닝 세트에 존재하는 라벨링된 모델 개수입니다. | |
|
라벨링 |
모든 뷰에 존재하는 라벨링된 모델 개수입니다. | |
|
Recall |
해당 도구가 라벨링된 모델을 찾을 가능성이 얼마나 높은가입니다. Recall은 실제로 원하는 모델이 있을 때 신경망이 이를 얼마나 빠짐없이 잘 찾아낼 수 있는지와 관련된 능력입니다. 이는 정확하게 마킹된 모델 수를 라벨 지정된(라벨링된) 모델 수로 나눈 값입니다. Recall 점수가 높으면, 라벨 지정된 모델을 최대한 모두 찾게 되므로 좋습니다. 하지만 Recall은 부정확하게 발견된 것은 고려하지 않으므로, 높은 Recall이라도 제 1종 오류를 의미할 수도 있습니다. 자세한 내용은 기본 개념: False Positives, False Negatives를 확인하십시오. |
|
|
Precision |
얼마나 정확하게 라벨링된 모델을 찾아내는가입니다. Precision은 모델을 정확히 찾아내는 신경망의 능력입니다. 이는 정확하게 마킹된 모델 수를 발견된 전체 모델 수로 나눈 값입니다. Precision 점수가 높으면 발견된 모든 모델이 이미지에 존재함을 나타내는 것이므로 좋습니다. 하지만, 높은 Precision은 실제로 뷰에 존재하지만 발견되지는 않은 모델을 고려하지 않으므로, 검출되지 않은 모델이 훨씬 많은 상황인 제 2종 오류가 발생할 수 있습니다. 자세한 내용은 기본 개념: False Positives, False Negatives를 확인하십시오. | |
|
F-Score |
Precision과 Recall의 조화 평균입니다. |
기본 개념: False Positives, False Negatives
통계적 결과 외에도, 이 결과에 따라 False Positive 및 False Negative 결과가 어떤 영향을 받는지도 이해해야 합니다.
이미지에서 결함을 찾아내는 이미지 검사 기계가 있다고 가정해보겠습니다. 이 기계가 어떤 이미지에서 결함을 찾아낸다면 이 이미지 검사 결과는 Positive라고 하고, 어떤 결함도 찾지 못하면 검사 결과를 Negative라고 합니다. 이 때, 검사 결과 통계치는 다음과 같이 요약될 수 있습니다:
-
False Positive (또는 제1종 오류)
-
feature가 특정 클래스에 실제로는 속하지 않음에도 불구하고 이미지 검사기는 이 특정 클래스에 속한다고 판단함.
-
-
False Negative (또는 제2종 오류)
-
feature가 특정 클래스에 실제로는 속함에도 불구하고 이미지 검사기는 이 특정 클래스에 속하지 않는다고 판단함.
-
기본 개념: Precision, Recall, F-Score
False Positives와 False Negatives는 모든 VisionPro Deep Learning 도구들에서 쓰이는 통계적 결과값들인 Precision과 Recall로 요약되어 표현됩니다.
- Precision
- 일반적으로, 낮은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 feature를 정확하게 검출하는 데 실패하며, 따라서 많은 False Positive(제1종 오류)가 발생합니다.
- 일반적으로, 높은 Precision을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 feature를 정확하게 검출하는 데 성공하지만, 만약 Recall이 낮을 경우 많은 False Negative(제2종 오류)가 발생할 가능성이 있습니다.
- Recall
- 일반적으로, 낮은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 feature를 충분히 검출하는 데 실패하며, 따라서 많은 False Negative(제2종 오류)가 발생합니다.
- 일반적으로, 높은 Recall을 보이는 신경망은 주어진 이미지 데이터(테스트 데이터)에서 feature를 충분히 검출하는 데 성공하지만, 만약 Precision이 낮을 경우 많은 False Positive(제1종 오류)가 발생할 가능성이 있습니다.
요약하면,
- Precision - 라벨 지정된 feature와 일치하는 feature를 검출한 백분율.
- Recall - 도구에 의해 정확하게 식별된, 라벨 지정된 feature의 비율.
- F-Score – Recall과 Precision의 조화 평균.
거의 모든 검사 사례에서 (예외가 있을 수 있음) 이상적인 통계적 결과는 높은 Precision과 높은 Recall을 동시에 보이는 결과입니다.
노드 모델 점수
Blue 위치 도구에서 모델 점수(모델 매치 점수)는 2가지 기준을 함께 사용해 계산합니다:
-
이 모델에 있는 feature들 점수의 평균값
-
이 모델에 있는 feature들의 위치에 기반한 "위치 점수(geometry score)"
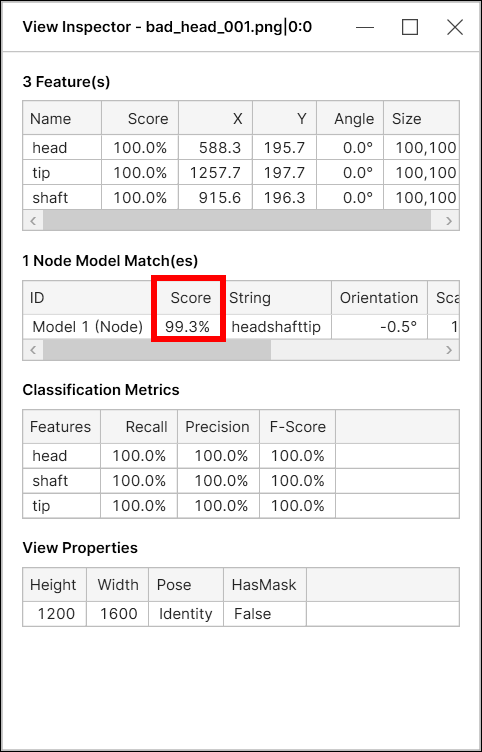
모델 매치 점수 계산에 feature들의 공간적 배열을 고려하기 때문에, 모든 feature들이 만점인 100%를 가져도 이 위치 점수가 100% 미만이면 모델 점수는 100%보다 낮을 수 있습니다.
"위치 점수"는 feature들 실제 위치가 모델에서 정의한 노드들 위치와 상대적으로 얼마나 다른지를 평가하는 점수입니다. 예를 들어, 노드가 3개이고 각 노드 점수가 모두 100%일 때 이 노드 모델 점수는 100%보다 약간 작을 것입니다. 왜냐하면 feature들이 위치한 모습이 모델에서 설정한 feature 위치와 완벽하게 같은 것이 아니라면 이 모델의 위치 점수는 100%보다 작기 때문입니다.
레이아웃 모델 점수
Blue 위치 도구에서 레이아웃 모델 점수(모델 매치 점수)는 이 모델에 있는 feature 점수들의 평균값입니다.