マスク
すべての Cognex VisionPro Deep Learning ツールでは、マスクを作成して適用することによって、画像の一部を学習から除外する機能をサポートしています。
学習中および処理中に、Deep Learning ツールは、サンプリング領域の公称範囲 (ピクセル単位) である特徴のサイズを使用して、画像をサンプリングすることによって機能します。サンプリング中は、サンプル領域周辺からの大量のコンテキスト情報 (コンテキスト領域) も考慮されます。
|
|
|
|
1 |
特徴のサイズ |
|
2 |
サンプリング領域 |
|
3 |
コンテキスト領域 |
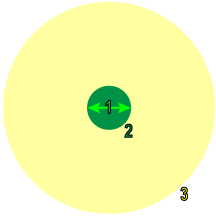
画像にマスクが適用されると、サンプリング領域内のマスクされたピクセルは必ず破棄されます。ただし、コンテキスト領域にマスクがどのように適用されるかは、[マスキングモード] パラメータによって決まります。
架空のサンプリング領域とコンテキスト領域がある、次のマスクされた画像について考えてみます。

[マスキングモード] パラメータがデフォルトの [透明] に設定されている場合、画像のマスクされていない部分だけでサンプルが収集されます。ただし、コンテキスト情報は、コンテキスト領域内の明るい緑色の領域で示されるマスクされた領域からも収集されます。
![]()
[マスキングモード] パラメータが [マスク] に設定されている場合、コンテキスト領域内の明るい赤い領域で示される、コンテキスト領域内でマスクされたピクセルはすべて破棄されます。この設定は、サンプリング中にツールに ROI の中心にフォーカスすることに効果的に集中させます。
