红色分析的混淆矩阵
混淆矩阵是对真值![]() 真值指的是机器学习模型所要解决问题的实际性质,这一性质通过相关示例数据集得以体现。监督式机器学习模型在标注数据上进行训练,这些数据被视为模型识别模式的基础,从而能够预测新数据中的标注。与工具预测之间关系的直观表示。
真值指的是机器学习模型所要解决问题的实际性质,这一性质通过相关示例数据集得以体现。监督式机器学习模型在标注数据上进行训练,这些数据被视为模型识别模式的基础,从而能够预测新数据中的标注。与工具预测之间关系的直观表示。
|
|
|
| 数字 | 说明 |
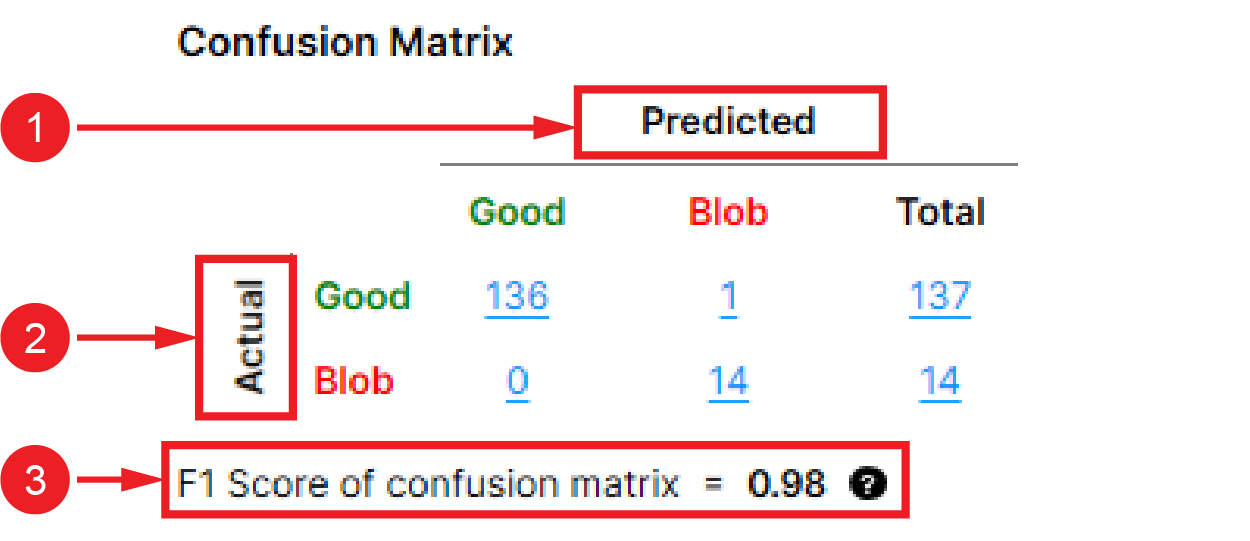
| 1 |
水平维度显示了该工具的预测。 |
| 2 | 矩阵的垂直维度显示您分配的实际标注 |
| 3 |
混淆矩阵的 F1 得分是精度和召回指标的结合。F1 得分是衡量分割 有关应用程序如何在混淆矩阵中计算精度、召回和 F1 分数的更多信息,请参见精度、召回和 F1 得分计算示例。 注意: 混淆矩阵的精度、召回和 F1 得分的计算方法与区域面积指标部分的像素级别计算方法不同。
|
混淆矩阵与多个缺陷类
如果红色分析工具有多个缺陷类,则混淆矩阵每次只显示一个缺陷类别的结果。您可以使用数据库概述右上角的下拉菜单在缺陷类别之间切换。
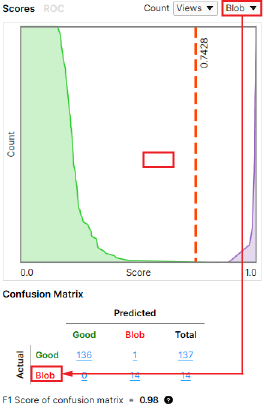
混淆矩阵仅将所选缺陷类计为“不良”,并将所有其他缺陷类计为“良好”.例如,对于缺陷类“Blob”来说,“良好”指的是所有“不是 Blob”的东西。这意味着“良好”和其他类的缺陷都计为“良好”。
混淆矩阵中的正负结果
您可以从真正值、真负值、假正值和假负值的角度查看混淆矩阵。精度和召回指标,以及最终的 F1 得分,都是根据这些结果计算得出的。
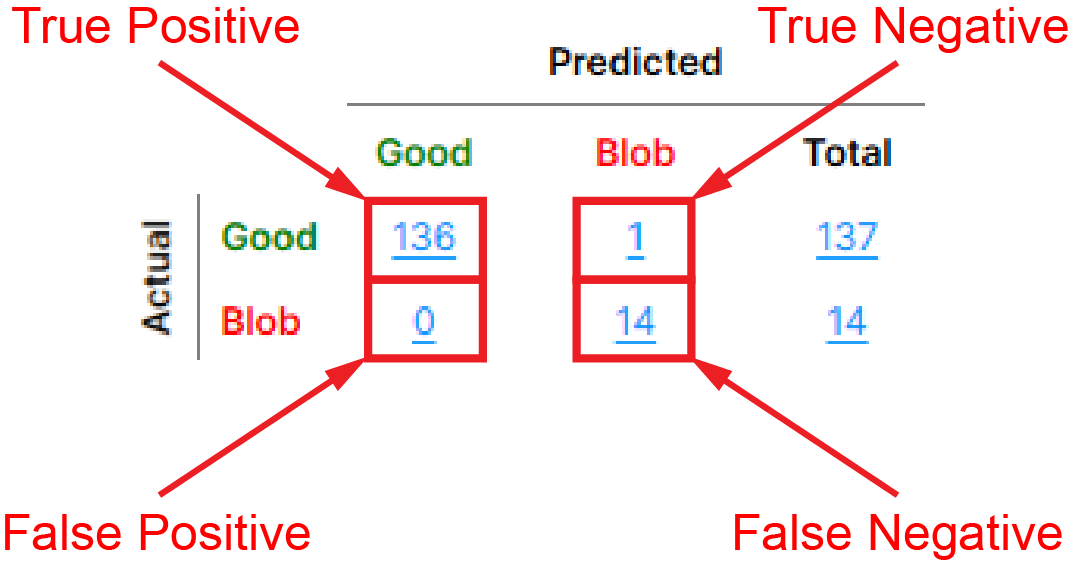
对于“良好”类:
-
一个“实际良好 - 预测良好”对表示一个真正值 (TP)
-
一个“实际不良 - 预测良好”对表示一个“假正值 (FP)”
-
一个“实际不良 - 预测不良”对表示一个真负值 (TN)
-
一个“实际良好 - 预测不良”对表示一个假负值 (FN)
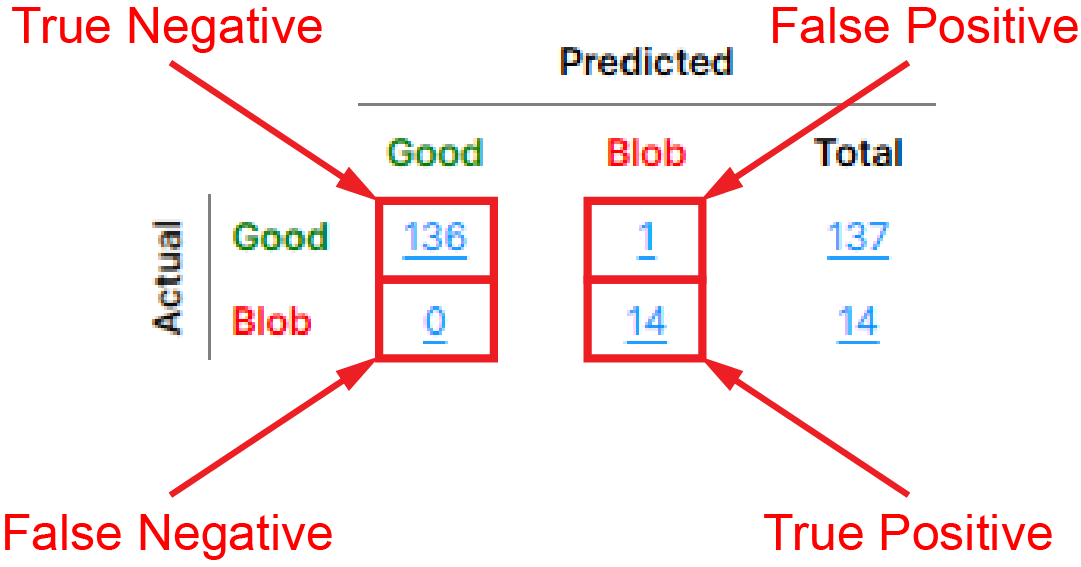
对于“不良”类别(或选定缺陷类别):
-
一个“实际不良 - 预测不良”对表示一个真正值 (TP)
-
一个“实际良好 - 预测不良”对表示一个假正值 (FP)
-
一个“实际良好 - 预测良好”对表示一个真负值 (TN)
-
一个“实际不良 - 预测良好”对表示一个假负值(FN)
有关正值和负值结果的详细信息,请参阅正、负和假结果。
精度、召回和 F1 得分计算示例
精度和召回指标,以及最终的 F1 得分,是基于真正值 (TP)、真负值 (TN)、假正值 (FP) 和假负值 (FN) 结果的计数计算得出的。有关更多信息,请参阅 。
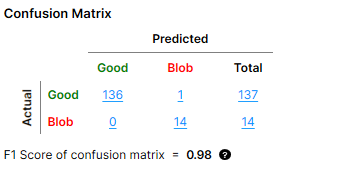
要计算上图中混淆矩阵示例的指标:
-
计算“良好”类的混淆矩阵的精度、召回和 F1 得分:
-
精度 = TP / (TP + FP) = 136 / (136 + 0) = 1
-
召回 = TP / (TP + FN) = 136 / (136 + 1) = 0.993
-
F-得分= 2 * 召回 * 精度 / (召回+精度) = 2 * 0.993 * 1 / 1.993 = 0.996
-
-
计算“Blob”类的混淆矩阵的精度、召回和 F1 得分:
-
精度 = TP / (TP + FP) = 14 / (14 +1 ) = 0.933
-
召回 = TP / (TP + FN) = 14 / (14 + 0) = 1
-
F-得分 = 2 * 召回率 * 精度 / (召回 + 精度) = 2 * 1 * 0.933 / 1.713 = 0.965
-
-
计算混淆矩阵的 F1 得分:
-
0.5 * (“良好”类的 F 得分) + 0.5 * ("Blob"类的 F 得分) = 0.5 * 0.996 + 0.5 * 0.965 = 0.98
-