创建模型
模型
蓝色定位 和 蓝色读取 的模型是按照某种图案出现的一组特征。该图案可以是几何位置(节点模型),也可以是相互粘合的字符特征的数量(蓝色读取 中的字符串模型)。例如,节点模型可以是一组 5 个特征,根据它们的相对几何位置形成星形形式。模型就像标签一样,因此您可以将其视为“组标签”。通过创建模型,可以定义由按视图中特定图案显示的多个特征组成的标签。与单个特征标签一样,应该在每个视图上定义和创建(标注的)模型。但是蓝色定位和蓝色读取中的模型不是神经网络,并且它是不可训练的。在处理之后,可以/无法在每个视图上正确地找到模型,因此视图中可能存在匹配/不匹配的模型。
当图像中的字符被组织为常规、一致的组时,定义模型将提高性能。您可以在蓝色读取中定义三种类型的模型:
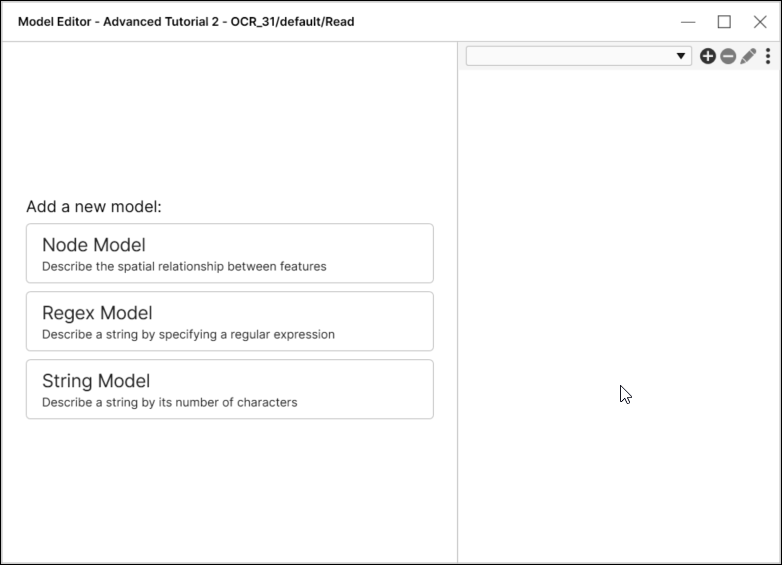
- 节点模型
- 字符串模型
- 正则表达式模型
要创建模型,请从“工具”菜单中选择编辑模型,这将启动“模型编辑器”对话框。选择要创建的模型的类型。
- 如果已定义一到多个模型,则工具将使用模型信息,通过尝试将找到的字符拟合到已定义的模型并使用分数最高的模型来提高其性能。
- 在性能方面,正则表达式模型的执行速度通常是最快的,而节点模型通常是最慢的。
蓝色读取节点模型
可以创建描述一组特征之间的空间关系的节点模型,以及哪些字符值(数字或大写字母)对于模型中的每个节点是合法的。节点模型用于在每个图像中应包含相同数量字符的字符串。例如,在字符沿弧线放置的情况下,它们也很有用。
如何创建节点模型
要使用节点模型,请执行以下操作:
- 在添加工具、配置 ROI定义感兴趣区域 (ROI)并设置字符特征尺寸(采样参数),处理工具(按下“书本”图标)。
-
选择要包含在节点模型中的所有黄色已找到特征(按住 Shift 键单击或按住 Shift 键拖动以绘制方框),然后右键单击所选字符并选择创建模型。

 注意:如果选择创建模型而未选择任何内容,则将根据图像中的所有特征创建模型。
注意:如果选择创建模型而未选择任何内容,则将根据图像中的所有特征创建模型。 -
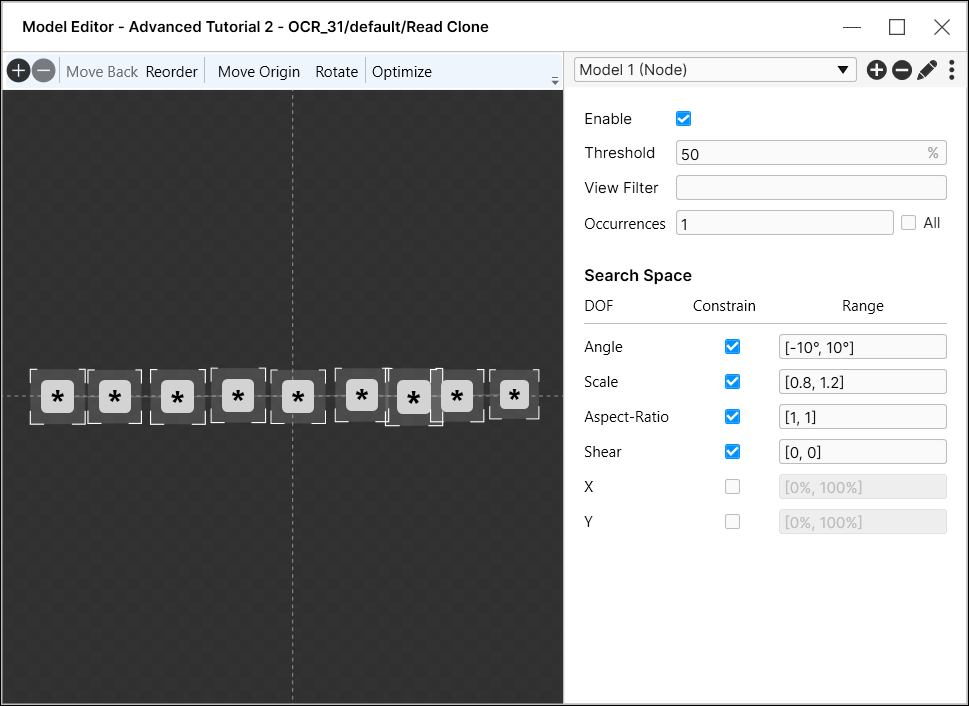
在“模型编辑器”对话框中定义节点模型。
-
对于模型中的每个节点,可以优化节点的特征,例如指定它应该是数字还是大写字母字符(默认为该节点可以是任何类型的字符)。
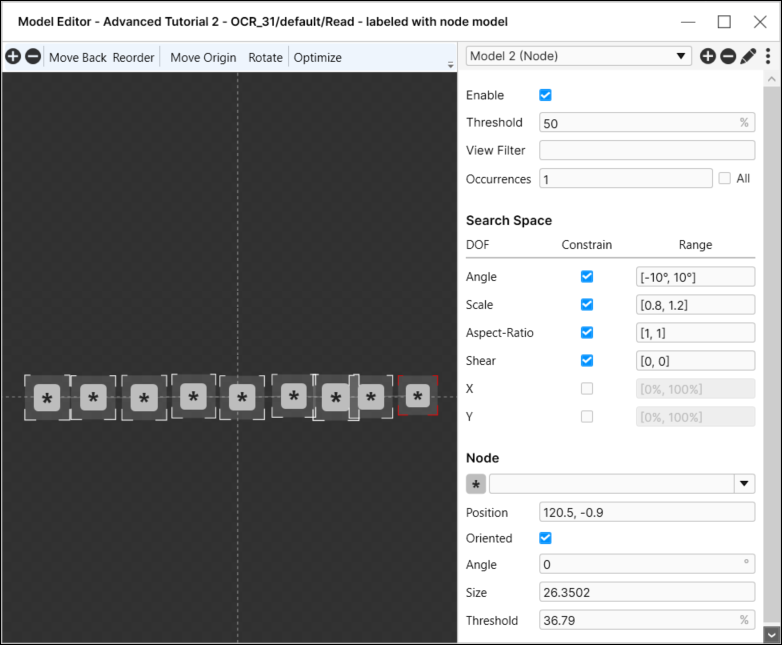
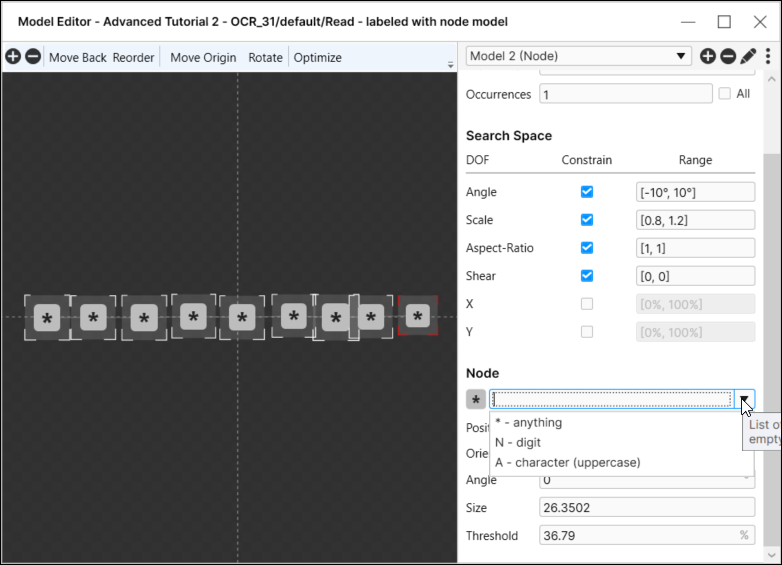
要指定节点的特征,请选择该节点,这将打开所选实例的节点设置。
- 通过按下对话框右上角的 X 按钮关闭对话框。
- 然后,模型将应用于启动“模型编辑器”时打开的视图。
- 处理工具(按下“书本”图标)将模型应用于其余视图。
- 审核结果。
节点模型编辑器
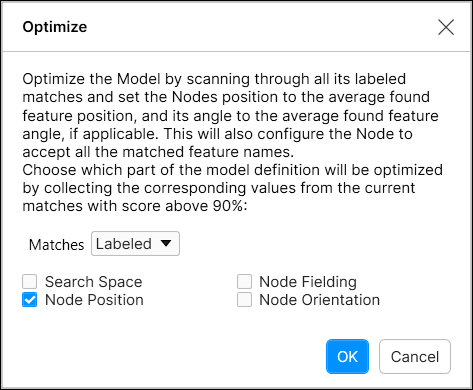
优化
| 参数 | 说明 |
|---|---|
|
优化 |
“优化”选项使用工具上次运行的结果(标记),并根据标记优化模型中节点的几何形状和位置(您可以选择与复选框一起使用的节点)。 通常,在创建节点模型时,可以指定从一个图像中找到的节点的几何形状。通过“优化”选项可根据多个图像调整节点位置。 |
|
启用 |
指定模型是否应处于活动状态。 |
|
阈值 |
指定确定为模型匹配的最低分数。 |
|
视图筛选条件 |
指定筛选工具以确定将应用模型的视图。使用时,将为满足筛选条件的视图选择性地启用模型。 |
|
出现次数 |
指定应该检测到多少个模型实例。启用“全部”复选框,工具将检测所有模型实例。 |
|
搜索空间 |
|
|
限制 |
启用“约束”复选框后,将限制模型与为自由度 (DOF) 参数指定的范围的匹配。如果禁用,则无论为 DOF 参数指定的范围如何,模型都将匹配,并且范围值将变灰,从而指示其未激活。 |
|
角度 |
指定模型可能展示的可能方向。 |
|
比例 |
指定要视为匹配所允许的整体模型大小和节点间间距偏差的偏差量。例如,[0.8,1.2] 的值将指定模型的总体大小必须在标称大小的 80% 和 120% 之间,并且模型中任何两个节点之间的间距也必须在标称间距的 80% 和 120% 之间。 |
|
宽高比 |
指定要视为匹配所允许的整体模型宽高比以及节点间宽高比的偏差量。 |
|
剪切 |
指定要视为匹配所允许的模型剪切映射以及节点间剪切的偏差量。 |
|
X |
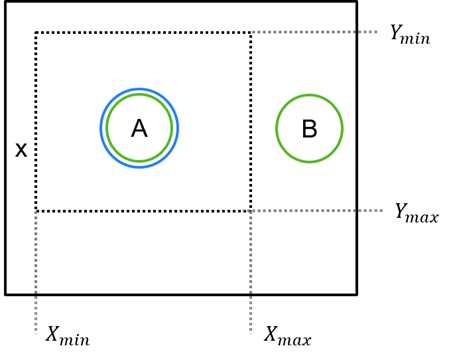
X 和 Y 参数指定视图中的搜索区域,以百分比表示。例如,要仅搜索视图的左上象限,您应将 X 和 Y 都指定为 [0%, 50%]。使用这些设置,将仅返回所有节点位于指定区域内的模型匹配。 在下面所示的示例中,A 匹配,但 B 在 X 和 Y 范围之外,因此无法形成 A-B 模型。
|
|
Y |
|
| 节点 | |
|
位置 |
指定选中节点的预期像素位置。 |
|
*(字符类型) |
指定应在所选节点处匹配的字符类型。 |
| 定向 |
指定此节点是否是定向节点。如果启用了该参数,将激活下面的角度参数,并且只有具有该特定角度的字符特征才会与所选节点匹配。 |
| 角度 | 指定此节点的方向(以度为单位)。仅在启用方向参数时才能激活此参数。 |
| 大小 | 指定此节点的大小。 |
| 阈值 | 指定应与所选节点匹配的最小特征分数。 |
蓝色读取 字符串模型
字符串模型是最容易使用和定义的模型。您只需定义希望找到的最小字符数,以及您希望在图像中遇到的字符与 ROI 水平边界之间的角度变化。
如何创建字符串模型
要使用字符串模型,请执行以下操作:
- 在添加工具、配置 ROI定义感兴趣区域 (ROI)并设置字符特征尺寸(采样参数),处理工具(按下“书本”图标)。
-
要创建字符串模型,请从“工具”菜单中选择编辑模型,然后从“模型编辑器”对话框中选择字符串模型。
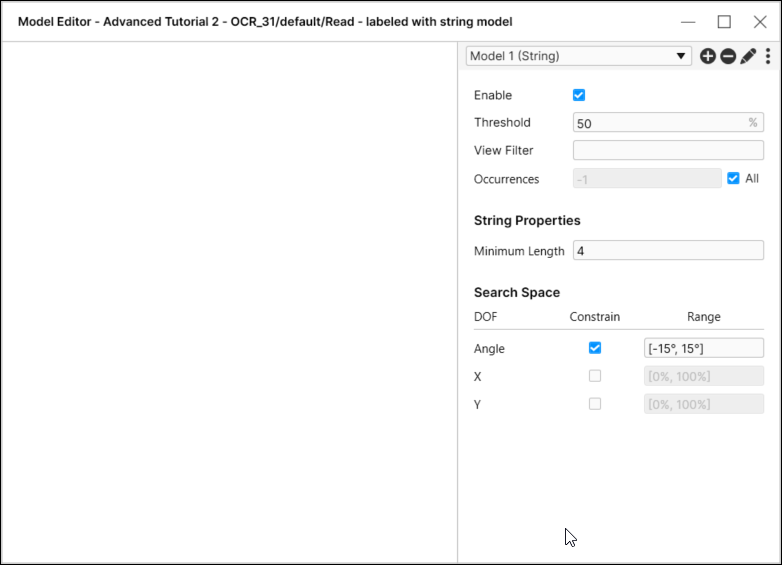
- 在最小长度字段中输入字符串应包含的字符数。
- 该工具将返回 ROI 中存在的指定数量的字符。匹配的字符必须沿一条水平线分布,该水平线由角度参数定义,是相对于 ROI 水平轴的允许偏差。
- 通过按下对话框右上角的 X 按钮关闭对话框。
- 然后,模型将应用于启动“模型编辑器”时打开的视图。
- 处理工具(按下“书本”图标)将模型应用于其余视图。
- 审核结果。
蓝色读取正则表达式模型
正则表达式模型可提供灵活的控制,通过让您定义希望借助正则表达式查找的字符,从而定义感兴趣字符串的精确格式。
如何创建正则表达式模型
要使用正则表达式模型,请执行以下操作:
- 在添加工具、配置 ROI定义感兴趣区域 (ROI)并设置字符特征尺寸(采样参数),处理工具(按下“书本”图标)。
-
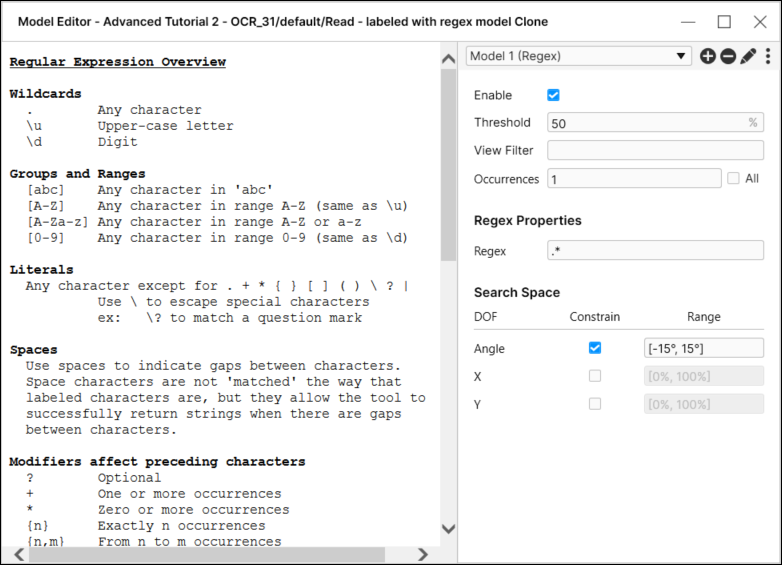
要创建正则表达式模型,请从“工具”菜单中选择编辑模型,然后从“模型编辑器”对话框中选择正则表达式模型。
-
在正则表达式字段中定义正则表达式。
注意:- 构造正则表达式时,最简单的通配符是句点,即“匹配任何单个字符”。然后,您可以在字符或通配符后使用修饰符来指定要匹配的字符数。
- 正则表达式模型的最小匹配长度是三个字符(不包括空格字符)或更长。
- 正则表达式模型将返回 ROI 内与您的正则表达式相匹配的字符。匹配的字符必须沿一条水平线分布,该水平线由角度参数定义,是相对于 ROI 水平轴的允许偏差。
- 通过按下对话框右上角的 X 按钮关闭对话框。
- 然后,模型将应用于启动“模型编辑器”时打开的视图。
- 处理工具(按下“书本”图标)将模型应用于其余视图。
- 审核结果。
正则表达式句法
正则表达式模型使用以下句法:
| 代码 | 定义 |
|---|---|
|
。 |
匹配任何字符,但不包括空格。 |
|
[A-Za-z] |
匹配任何英文字符。请参阅下面的“字符类”。 |
|
[^A-Z] |
匹配任何字符,但不包括空格和大写字符。 |
|
\d, \u |
分别相当于 [0-9] 和 [A-Z]。 |
|
jan|feb |
匹配 “jan” 或 “feb” |
|
() |
组字符。有利于后跟 ?、*、+、或 {5},或使用 | 来界定或/或表达式范围的情况。 |
|
空格 |
空间是特殊字符。它与任何特征都不匹配,但会告知蓝色读取工具的模型匹配器会在此处特征之间存在更长间隙,这会影响评分。 |
|
\*, \?, \+, \(, \), \[, \], \{, \}, \., \|, \\ |
将文字控制字符转义。 |
|
? |
前面的表达式是可选的。 |
|
* |
前面的表达式重复 0 次或更多次。 |
|
+ |
前面的表达式重复 1 次或更多次。 |
|
{5} |
前面的表达式正好重复 5 次。 |
|
{5,8} |
前面的表达式重复 5 到 8 次(包括8次)。 |
|
其他字符 |
完全匹配该字符。 |
在字符类(例如 [a-z])内部,适用以下句法规则:
- A - 表示范围,除非它出现在类指定的开头(可能在 ^ 之后)或结尾。如果您需要字符 - ,请将其放在其中一个位置。
- 使用结束方括号 ] 结束此类,除非用 \ 将其转义,或出现在类指定的最前面(可能在 ^ 之后)。
-
如果你想要一个反斜杠,则应使用另一个反斜杠来将其转义。
注意:唯一具有特殊含义的字符是 ]、- 和 \。任何其他字符(例如 *、?、)、| 等)都有其字面含义,不应转义。
正则表达式字符串中的空格
在正则表达式字符串中使用空格(空白)字符表示字符之间的预期间隔。如果指定较大的间隙,工具可能会在匹配期间跳过字符。一般原则是,使用空格字符表示与指定特征尺寸一样大的间隙。
如正则表达式模型句法主题中所述,(普通 ASCII)空格字符是特殊字符。它与特征不匹配,但会告知模型匹配器应该在此位置的特征之间存在更大间隙。如果预期间隙更大,可以添加若干空格。模型的最终“匹配字符串”将包括这些空格。
空格是唯一的特殊字符。其他空白字符只是尝试匹配用该特定字符标注的特征。
正则表达式模型的 Unicode 字符匹配
正则表达式模型支持匹配 Unicode 字符,但需要注意的是,它以 Unicode 代码点为单位运行:假设每个特征对应于 Unicode 代码点。
Unicode 提供所谓的预合成字符,即只包含单个代码点的字符(即使带有变音符号)。为确保使用这些,用户应使用 Unicode 规范化形式 NFC。(带有 dakuten或 handakuten 变音符号的半宽日语假名是值得注意的例外情况,这些符号在 Unicode 中没有预先组合的形式。)
正则表达式模型和空特征
标记用于训练的字符时,在添加已标记特征后,但在为其提供字符之前,该字符存在于特殊的“空”状态。作为一种特殊情况,正则表达式模型将始终能够匹配空特征,与使用的字符类或文字字符无关。这有助于您使用模型的工作流程将许多特征的真值作为一个字符串输入。
使用模型
如果您在蓝色读取工具中定义了一个或多个模型,则从某些重要角度而言,标注图像的过程会简化并加快。
-
当您开始标注没有找到特征的图像时,您标记了几个字符之后,工具就会建议可能的模型位置,包括模型中所有特征的位置:

模型出现后,您只需在文本字段中键入正确的字符值,工具就会自动创建所有标签:

指定字符值后,还需要调整特征位置以保证其正确:

-
当您从具有已发现特征的图像开始时,过程甚至更为简单。只需右键单击并选择接受视图即可:
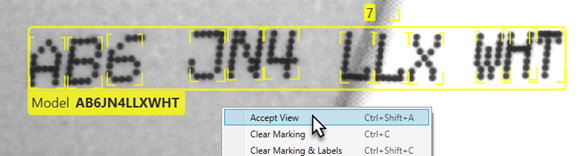
在这种情况下,只有模型匹配的特征才会转换为标签:

导入/导出模型
与蓝色定位相似,蓝色读取模型还支持导出和导入到其他蓝色读取工具。由此,您可以根据现有模型,通过导入以前创建的模型来快速创建新模型。
导出模型时,VisionPro Deep Learning 将有关模型的所有信息打包到模型存档文件中。然后,将模型存档文件导入另一个蓝色读取工具时,将创建模型的副本。有关如何导入/导出模型的详细信息,请参见 导入/导出模型。