점수와 ROC 곡선
Red 분석 결과는 점수와 ROC 곡선으로 측정됩니다.
점수
Red 분석 도구 High Detail 모드에서 뷰의 전반적 점수는 해당 뷰 내의 결함 확률의 최댓값을 말합니다. 이 모드의 Red 분석 도구는 input 이미지의 각 픽셀 위치에 대해 해당 픽셀이 결함일 확률을 보여주는 확률맵을 반환합니다. 결함 확률은 해당 픽셀이 결함일 확률과 해당 픽셀이 배경일 확률을 더한 값이 1.0이 되도록 정규화됩니다.
점수 그래프는 라벨 지정되고 점수가 계산된 모든 이미지와 두 개의 임계치(T1, T2)를 나열합니다. 첫 번째 임계치는 True Negative(결함 없음)이 그 값에 대해 불확실해지지 않기 위해 가질 수 있는 최대값을 결정합니다. 두 번째 임계치는 True Positive(결함 있음)으로 간주되기 위해 가져야 하는 최소값을 결정합니다. 둘 사이의 값은 라벨에 따라 False Positive 또는 False Negative로 간주되며, Confusion Matrix에서 Confusion Matrix에서 Inter 열에 할당됩니다.
T1과 T2 임계치를 이용해 Inter(또는 한계) 클래스를 생성하십시오. 이를 만나게 되면, 인간 검사자가 검토할 수 있도록 이미지에 Inter 플래그를 지정하는 절차를 설정할 수도 있으며, 이러한 이미지를 저장해 추가적으로 (오프라인 상태에서) 다시 트레이닝할 수도 있습니다. 또 다른 안전 장치로, 이 범주의 이미지는 거부하고 재작업 통으로 보낼 수도 있습니다.
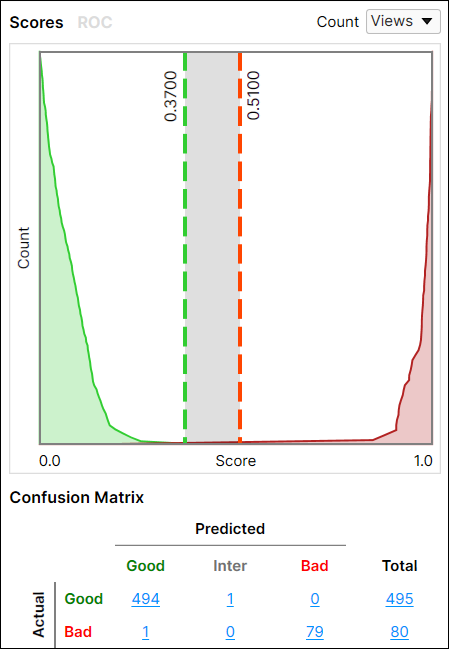
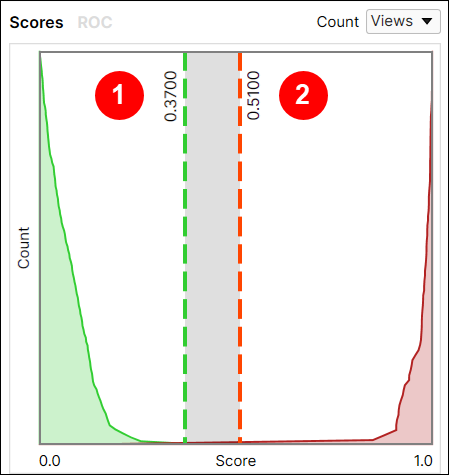
두 임계치 모두(T1 및 T2, 아래 그림에서 T1 = 0.37, T2 = 0.51) 그래프에서 조정할 수 있습니다. 이 값들을 조정하면, 임계치 매개변수 설정도 조정됩니다.
-
여기에 임계치를 설정하면, 도구는 결함 예측에 덜 까다로워져, False Positive가 많아집니다.
-
여기에 임계치를 설정하면, 도구는 결함 예측에 더 까다로워져, False Negative가 많아집니다.
점수 카운트 필터
점수 카운트 필터를 이용하면 도구에 의해 반환되는 통계량을 필터링할 수 있습니다.
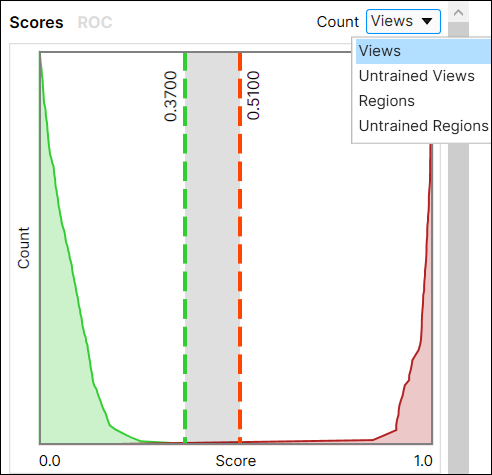
- Views: 각 뷰에서 점수가 가장 높은 영역을 반환합니다.
- Untrained Views: 트레이닝 되지 않은 각 뷰에서 점수가 가장 높은 영역을 반환합니다.
- Regions: 영역의 픽셀 수준 점수를 종합한 점수를 반환합니다(이렇게 하려면, 영역에 라벨을 지정해야 합니다).
- Untrained Regions: 트레이닝되지 않은 영역의 Pixel level(픽셀 수준) 점수를 종합한 점수를 반환합니다(이렇게 하려면, 영역에 라벨을 지정해야 합니다).
트레이닝되지 않은 뷰가 없다면, 히스토그램에는 아무것도 표시되지 않습니다.
라벨 지정된 영역이 없다면, 다음이 적용됩니다.
- 영역에 대한 카운트 필터는 뷰의 카운트 필터와 같은 것을 대상으로 합니다.
- 트레이닝되지 않은 영역에 대한 카운트 필터는 트레이닝되지 않은 뷰와 같은 것을 대상으로 합니다.
ROC(수신자 조작 특성) 곡선
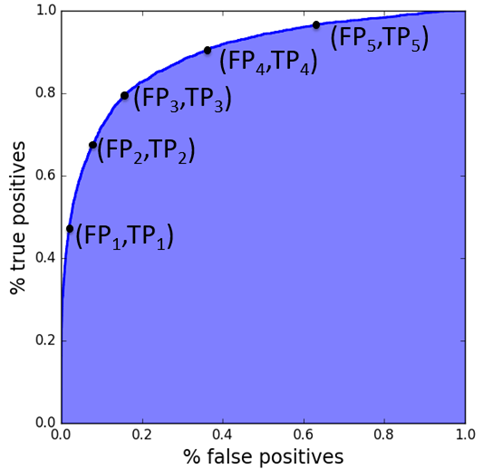
수신자 조작 특성(Receiver Operating Characteristic, ROC) 곡선은 주어진 특정 임계치에 대해서, 특수성에 대한 민감도를 측정합니다.
- 민감도는 Positive 결과(결함 있음)를 검출하는 능력입니다.
- 특수성은 Negative 결과(결함 없음)를 검출하는 능력입니다.
이는 두 임계치 사이의 결과를 평가함으로써 수행됩니다.
AUC(곡선 아래 면적)
아래에서는 곡선 아래 면적(AUC)의 통계적 해석 방법을 다룹니다. AUC는 결과가 얼마나 잘 얻어지는지를 결정합니다. AUC에서 일반적으로, 1은 완벽한 결과이며, 0.8 이상이면 (일반적으로 말할 때) 양호한 결과이고, 0.5면 완전히 무작위인 결과입니다.
AUC는 모든 임계치와 독립적이며, 점수의 분포에 대해 아무런 가정 없이, 점수의 순위에만 따른 통계적 테스트를 제공합니다. AUC는 classifier(분류자)의 separation power(분별력)에 대한 안정적인 지표입니다.
AUC의 특징은 다음과 같습니다.
- 무작위 분류자의 경우 0.5
- 완벽한 분류자의 경우 1
- 백분율이 아님
- 모든 임계치와 독립적임