신경망 프로세싱(추론)
런타임에는, 런타임 이미지의 각 샘플이 트레이닝된 해당 도구의 네트워크를 이용해 개별적으로 프로세싱되며, 각 샘플마다 개별적인 네트워크 응답이 얻어집니다. 네트워크로부터의 응답은 확률맵으로 표현되는데, 여기에서는 input 이미지의 샘플 영역 각 픽셀에 확률이 할당됩니다. 확률 지도의 의미는 어떤 도구를 사용하는가에 따라 다릅니다. Red 분석 도구 Focused 지도 모드에서, 응답은 샘플링 영역 내 각 픽셀이 이미지 결함 내에 있을 확률입니다. 이러한 전체 이미지 확률맵은 보간법에 의해 네트워크 응답을 개별 샘플에 적용해 얻어집니다. 사용자에게 반환되는 최종 결과(feature pose 및 ID, 결함 영역)은 사용자가 결함 확률에 임계치를 지정함으로써 제어하는 결과 형성 과정에 기초합니다.
위 상황에서, 도구가 반환하는 확률은, 특정 판단이 얼마나 가능성이 높은가 하는 일반적인 인식을 잘 반영하지 않을 수 있음을 이해해야 합니다. 이는 주로 도구들이 "세계에 대한 제한적 관점"을 갖고 있기 때문입니다. 즉, 사람들의 광범위하고 풍부한 시각적 경험에 대한 확률을 반환하는 것이 아니고, 해당 도구가 몇 개의 클래스로 구성된 매우 제한적인 세계에 대한 확률을 반환하기 때문입니다.
어떤 도구 학습이 정상적으로 완료되었다면 학습 후에 프로세싱(추론)이 자동으로 실행됩니다. 트레이닝한 도구를 다시 프로세싱하려면, ![]() 버튼을 클릭하십시오.
버튼을 클릭하십시오.
프로세싱 시 Feature 샘플링
런타임에서 각 input 이미지는 철저하게 샘플링되며, 개별 샘플은 트레이닝된 네트워크에 의해 프로세싱됩니다. 트레이닝에 이용된 feature 크기가 런타임에도 이용됩니다(트레이닝된 네트워크가 트레이닝 때 이용한 입력과 일관된 입력을 프로세싱하도록 보장).
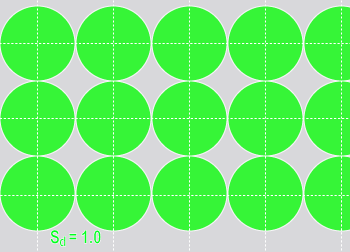
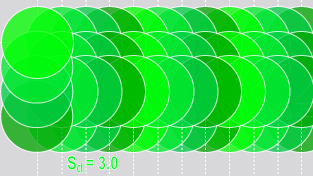
샘플링 밀도가 자동으로 결정되는 트레이닝과 달리, 런타임의 샘플링 밀도는 모든 Deep Learning 도구에서 사용자가 제어할 수 있습니다. 샘플링 밀도는 전후 샘플 간의 중복 정도를 결정합니다. 샘플링 밀도 비율이 1이면, 다음 샘플의 샘플링 위치가 feature 크기만큼 증가한다는 뜻입니다. 대부분의 도구는 샘플링 밀도 비율의 기본값이 3이며, 이는 샘플링 위치가 feature의 1/3만큼 증가하게 된다는 뜻입니다.
| 샘플링 밀도 = 1(4개의 샘플) | 샘플링 밀도 = 3(4개의 샘플) |
|---|---|
|
|
|

프로세싱 매개변수 설정
프로세싱 매개변수는 도구의 이미지 프로세싱 방식을 제어합니다. 딥러닝에서는 ‘inference(인퍼런스, 추론)이라고도 불립니다. 같은 모델을 활용하여 같은 이미지를 프로세싱하는 경우 결과는 항상 동일합니다. 이 매개변수를 변경해도 다시 학습할 필요는 없지만, 데이터베이스를 다시 프로세싱하기 때문에 그 효과는 바로 볼 수 있습니다. 도구를 다시 프로세싱하려면, ![]() 버튼을 클릭하십시오.
버튼을 클릭하십시오.
| 매개변수 | 설명 | ||||
|---|---|---|---|---|---|
|
Sampling Density(샘플링 밀도) |
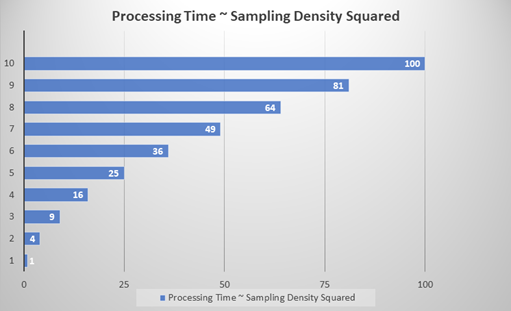
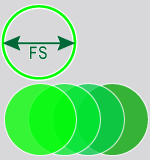
도구의 feature 크기(FS) 설정에 대한 샘플링 점의 밀도를 지정합니다. 샘플링 밀도는 전후 샘플 간의 중복 정도를 결정합니다. 샘플링 비율이 1이면, 다음 샘플의 샘플링 위치가 feature 크기만큼 증가한다는 뜻입니다. 대부분의 도구는 샘플링 비율의 기본값이 3이며, 이는 샘플링 위치가 feature의 1/3만큼 증가하게 된다는 뜻입니다. Tip: 샘플링 밀도 매개변수에서는 도구의 프로세싱 시간과 정확도와의 관계를 중요하게 검토해야 합니다. 도구의 프로세싱 시간은 대략 샘플링 밀도(Sd) 값의 제곱에 비례합니다. 예를 들어, 샘플링 밀도를 1로 설정하면, 3으로 설정할 때보다 9배(n2) 빠릅니다. 샘플링 밀도를 높게 설정하면 정확도가 높아지지만, 도구의 프로세싱 시간에 큰 영향이 있습니다.
|
||||
|
Threshold(임계치) |
T1과 T2([T1,T2]로 표현) 두 가지를 설정합니다. 이 값들은 검출된 영역을 정상 또는 불량으로 마킹할지 결정하는 임계치입니다. T1보다 작은 값은 정상으로 분류되며, T2보다 큰 값은 불량으로 분류됩니다. T1과 T2 값은 데이터베이스 개요에 있는 score(점수) 그래픽을 이용해 조정할 수도 있습니다. |
||||
| 자동 | 자동 (자동 임계치)를 활성화하면 데이터베이스 개요에 있는 Confusion Matrix의 F1 점수를 최대화하는 T1과 T2 임계치를 드롭다운 메뉴값을 따라서 자동으로 계산합니다. 4가지 드롭다운 메뉴값은 데이터베이스 개요의 카운트 드롭다운 메뉴값과 동일합니다. 자세한 내용은 점수 카운트 필터 항목을 참조하십시오. | ||||
|
Simple Regions(단순 영역) |
도구는 오직 "simple regions," 즉 구멍이 없는 폴리곤들만을 추출해야 함을 말합니다. |
||||
|
도구에서 발견된 영역의 기준으로 이용될 필터를 지정합니다. 필터를 지정하면, 필터와 일치하지 않는 영역은 결과에서 제거됩니다. 이 매개변수를 지정하지 않으면, 모든 영역이 반환됩니다. Note: 필터 syntax는 디스플레이 필터에 쓰이는 syntax와 동일합니다. 필터 syntax 작성에 대한 자세한 내용은 Custom Display Filters(사용자 정의 디스플레이 필터)를 참고하십시오.
사용 가능한 영역 속성은 다음과 같습니다.
|
|||||