Deep Learning for Vision
This topic explains how the VisionPro Deep Learning works by introducing its entire workflow.
Workflow Summary
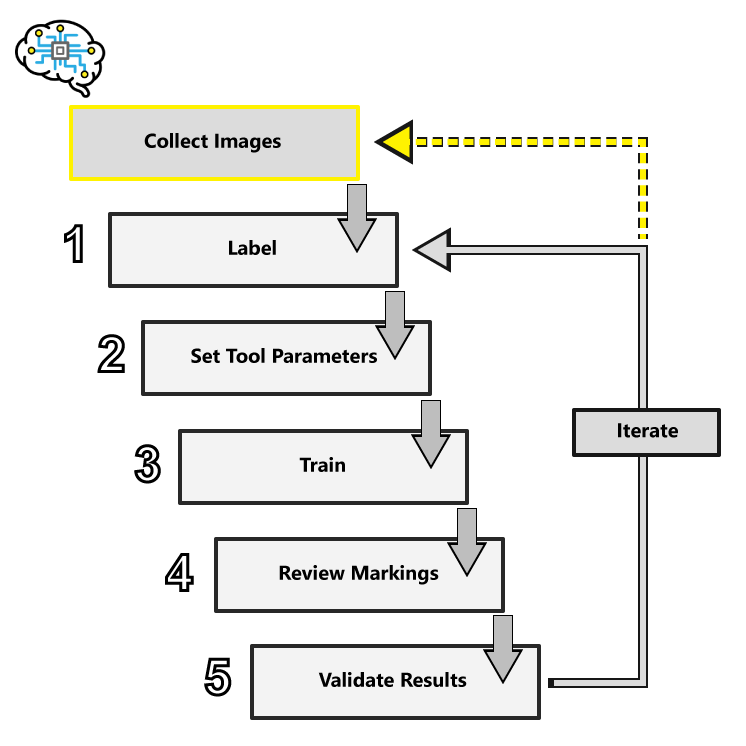
-
Collect Images
Follow the best practices for image quality in standard machine vision applications, where contrast is key. Within the image, defects and features must be human-distinguishable. Control all possible variables, such as consistent lighting, working distance, camera trigger timing, etc.
-
Label
This establishes the ground-truth for your tools, what is good or bad, what is a feature of interest, what a character is, what type of thing is in the image. It is important that you label all the views, and labeling must be accurate.
-
Set Tool Parameters
The Deep Learning tool parameters adjust how the network trains and processes images. The most common tool parameters to adjust are the following:
- Feature Size/Patch Size
- Training Set
- Perturbation parameters
- Sampling Density
Typically, the default settings of the parameters perform well against most image sets. Try training without adjusting any parameters beside Feature Size first.
-
Training
Training is the process that your tool, which is a neural network, is learning about the features (pixels) based on the labels you made. For example, a Red Analyze tool will learn the defect/normal pixels in each image based on the defect/normal labels you drew. The goal of the Red Analyze tool Training is learning enough to give the correct inspection results of whether an unseen image is defective or not. The key to training is to ensure that you include all possible variations within your training set, and that your images are accurately labeled. Training times vary by the application, tool setup and the GPU in the PC being used to train the network.
-
Review Markings
Markings represent Deep Learning's results for each image, and have unique graphic representations for each tool. Labels are generated by the developer. Markings are generated by Deep Learning.
-
Evaluate Results
Additional tool results are presented in the Database Overview panel. For each tool this includes the tool's processing time, scores and other statistical analysis.
Collect Images
The Deep Learning tools are capable of handling image and lighting variability, but the tools must be taught what that variability might entail. If the lighting may be brighter or darker from image to image, capture that variability in the images, and teach the tools using that variability in lighting by adding those images to your training image set.
When configuring your lighting and imaging options you can use typical machine vision lighting and optics techniques. However, with Deep Learning, you want to ensure that the lighting and optics are consistent between training and production. If, for example, you train your images based on a certain lighting and optic setup, and you then alter that configuration during production, the tool will be basing its performance on that initial setup, thus failing during production.
If possible, use controlled lighting to avoid effects caused by ambient lighting or visual changes that can be caused differences in the lighting setup. When setting up the cameras, make sure that the camera setup in the lab is the same as what will be used during production. Also attempt to minimize perspective distortion, changes in lens focus, depth of field and field of view.
Labeling
Since the Deep Learning software is based on learning, what the network is taught about the images is vitally important. Within the Deep Learning parlance, this process is termed “labeling.” Labeling is the process of a user identifying features or defects, and graphically illustrating them on the image. The label represents the “ground truth” for the tools and is used to train the tools and evaluate their performance.
The label is the ground truth for the tool, in other words, you are telling the tool, "this is what it should learn." The most important part of programming the tools is ensuring that the images that are being used for training are completely and accurately labeled. Without knowing the ground truth data for the images, you cannot tell whether the tool is working properly or not. Also, without accurate labeling, the tool's training will not work as well.
Labeling is the most important part of creating a deep learning application. Remember the following:
- When you are evaluating the performance of your tools and application, performance is always measured against the labeling that you provide. If your labeling does not reflect the actual ground truth for your images, then accurate and repeatable tool performance will not mean anything.
- When you train the Deep Learning tools, the goal for training – the cost function – is attempting to train the tool to produce a response that precisely matches the labeling that you provide.
Training
Neural network training is performed in the following general way:
- Each image in the image set that is being used for training is sampled across its full extent, using the specified Feature Size.
- The resulting samples are provided as input to the VisionPro Deep Learning deep neural network.
- For each sample, the neural network produces a specific response (depending on the tool type), and this response is compared with the image labeling associated with the sample's location in the training image.
- The internal weights within the network are repeatedly adjusted as the samples are processed and reprocessed. The network training system continually adjusts the network weights with a goal of reducing the error (difference or discrepancy) between the network's response and the labeling provided by the user.
- This overall process is repeated many times, until every sample from every training image has been included at least the number of times specified by the Epoch Count parameter.
|
|
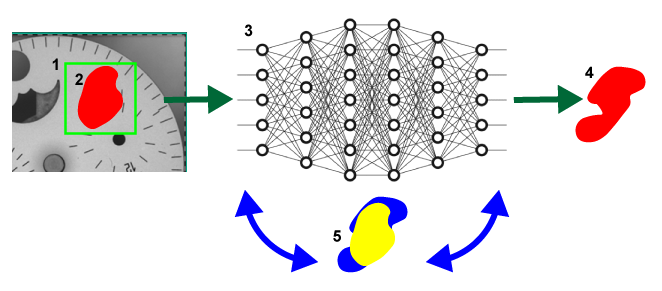
| Symbol | Definition |
| 1 | The sampling region. |
| 2 | The user-drawn, labeled defect region. |
| 3 | The neural network. |
| 4 | The response by the network. |
| 5 | The iterative process of adjusting the weights to reduce the discrepancy (in other words, error) between the labeled defect (in yellow) and the network response (in blue). |
The specific characteristics of the neural network training vary somewhat depending on the type of tool being trained. The largest single determinant that you can use to affect the network training phase is the composition of the training image set. The default behavior for all tools is to train using 50% of the images in the image set, with the images selected at random.
Review Markings
Markings are the graphical elements that the tools place over characters, features and/or areas of the image that the tool identified, based on the labeling done prior to being trained. Once the tool is trained, it can process images in the database, as well as newly acquired images, and place markings on the features it finds. For example, the Blue Locate requires that N number of features are labeled on the view. After the tool is trained, the result is reported in the form of a marking, which is a graphical overlay on the view.
To provide more labeled data for further training, you can convert some of the markings to labels. In this instance, you review the markings that the tool applied, and if you agree with the marking, you accept the view and convert the marking to a label.
Evaluate Results
Each of the VisionPro Deep Learning tools provides the following statistical results data:
- Confusion Matrix - This is a visual representation of the ground truth versus the tool's predictions.
- Recall - The percentage of labeled features or classes that are correctly identified by the tool.
- Precision - The percentage of detected features or classes that match the labeled feature or class.
- F-Score - The harmonic mean of Recall and Precision.
The use of these statistical metrics for each tool in VisionPro Deep Learning help qualify the following:
- Estimate future performance, for example, estimate rates of false positives.
- Optimize tool parameters by finding good parameter combinations or setting various thresholds.
- Test the reproducibility of model results.
The performance of a deep learning-based neural network model cannot be evaluated based on either of the following:
- A "grade" of the quality of the neural network model
- A neural network has no grade in terms of its quality.
- A "score" that is an output of the neural network model
- A neural network has several metrics that present its performance in a few different angles, but there is no single value that absolutely stands for a neural network's fitness and performance.