NVIDIA GPU 선택 및 구성
PC 시스템 구성의 선택은 도구의 정확성이나 행태에 영향을 주지 않으면서 도구 프로세싱 속도에 직접 영향을 주며, 가장 비싸면서 영향을 예측하기도 어렵습니다.
| 구성 옵션 | 빠른 이유 | 최선의 대안 | 주의 사항 |
|---|---|---|---|
|
NVIDIA 장치 유형 |
CUDA 코어의 수는 높은 Precision 프로세싱 속도 및 트레이닝에 직접 관련됩니다. 표준 텐서 코어의 수는 프로세싱 속도 및 트레이닝 속도에 직접 관련됩니다. 텐서 코어의 수는 낮은 Precision 모드에서의 프로세싱 속도에만 관련됩니다. 이 코어는 표준 Precision 프로세싱 또는 트레이닝 속도에는 영향이 없습니다. |
||
|
NVIDIA 드라이버 모드 |
소비자 등급 게이밍 지향 NVIDIA 장치는 WDDM 장치 드라이버 모델만 지원합니다. 이 드라이버는 연산이 아니라 그래픽 표시를 지원하기 위한 것입니다. 전문가 등급 NVIDIA 카드는 TCC 드라이버 모드를 지원하는데, 이는 성능과 안정성이 뛰어납니다. |
NVIDIA RTX / Quadro® 또는 Tesla(또는 일부 Titan) 브랜드의 NVIDIA 카드를 선택하십시오. |
GeForce 브랜드의 카드를 이용하면, NVIDIA 드라이버가 자주 업데이트되며 Deep Learning과 호환되지 않을 수 있으니 유의하십시오. TCC 모드 드라이버를 이용하면 GPU 카드의 비디오 출력 이용을 방지하며, 온보드 비디오를 대신 이용합니다. |
|
최적화 메모리 |
기본으로 활성화되어 있는 Deep Learning 최적화 메모리는 표준 NVIDIA GPU 메모리 관리 시스템을 재정의하여 성능을 개선합니다. |
카드가 4GB 이상의 메모리를 갖고 있도록 하십시오. TCC 드라이버를 이용하는 카드의 경우 성능 향상이 동등하게 두드러지지는 않습니다. |
|
NVIDIA 장치 브랜드 요약
다음 표는 다양한 NVIDIA 장치 유형을 요약합니다.
| 등급 | 소비자 | 전문가 | ||
|---|---|---|---|---|
|
제품군 |
로우엔드 게이밍 |
하이엔드 게이밍 |
워크스테이션 |
데이터 센터 |
|
브랜드 |
GeForce |
Titan |
NVIDIA RTX / Quadro® |
Tesla |
|
볼타 아키텍처 카드 |
없음 |
Titan V |
GV100 |
V100 |
|
파스칼 아키텍처 카드 |
GTX 1xxx |
Titan Xp |
G/GPxxx |
P100 |
|
튜링 아키텍처 카드 |
RTX 2xxx |
Titan RTX |
Quadro RTX4xxx |
T4 |
|
암페어 아키텍처 카드 |
RTX 3xxx |
Titan RTX 2nd Gen. (not released yet) |
Axxx | Axxx |
|
비디오 출력 |
예 |
예 |
예 |
No |
|
가격대 |
1천 달러 이하 |
3천 달러 이하 |
5천 달러 이하 |
5천 달러+ 이하 |
|
TCC 드라이버 지원 |
No |
예 |
예 |
예 |
|
ECC 메모리 |
No |
No |
예 |
예 |
|
텐서 코어 |
|
|
|
|
NVIDIA GPU 용어집
| 용어 |
정의 |
중요도 |
|---|---|---|
|
CUDA 코어 |
표준 NVIDIA 병행 프로세싱 장치. |
YES. CUDA 코어의 수는 NVIDIA GPU 프로세싱의 표준 지표입니다. CUDA 코어가 많을수록 VisionPro Deep Learning 프로세싱 및 트레이닝이 빨라집니다. |
|
ECC 메모리 |
오류 정정 코드(ECC) 메모리는 메모리의 읽기/쓰기에 오류가 없는지 여부의 확인을 지원합니다. |
NO. 신경망의 트레이닝 및 프로세싱은 막대한 양의 계산이 필요하므로, 메모리 오류가 도구 결과에 영향을 끼칠 가능성은 매우 낮습니다. |
|
TCC |
Tesla 컴퓨터 클러스터(TCC) 드라이버 모드 NVIDIA GPU의 계산적 활용에 최적화된 고성능 드라이버. TCC 고려 사항:
|
YES. 가능하면, TCC 드라이버 모드를 지원하는 카드를 선택하고, TCC 드라이버 모드를 사용하는 것이 좋습니다. |
|
텐서 코어 |
행렬 곱셈 연산을 전담하는 전체 Precision, 혼합 Precision(궁극적으로 정수 수학) 병렬 처리 단위. |
VisionPro Deep Learning 3.2.0 버전에 도입된 VisionPro Deep Learning은 사용자가 표준 또는 고급 라이센스를 가지고있는 한 더 빠른 처리 및 교육을 위해 텐서 코어를 자동으로 활용합니다. |
|
텐서 RT |
(낮은 Precision 및 이산 수학을 이용해) 텐서 코어가 있는 GPU에서 실행되는 TensorFlow, Caffe 및 기타 표준 프레임워크 네트워크의 런타임 성능을 최적화하는 NVIDIA 프레임워크. |
아니오. VisionPro Deep Learning은 텐서 RT와 호환되지 않는 고유의 네트워크 아키텍처를 이용합니다. |
GPU 자원 배분
High Detail 모드들에 GPU 자원들을 배분하는 로직에는 작지만 중요한 차이가 있습니다. 이 페이지에서 앞으로 더 쉽게 설명하기 위해, High Detail 모드와 Focused 모드는 각각 다음 도구들을 포함합니다. High Detail Quick 모드를 High Detail 모드 그룹에 포함한다는 정의는 이 문서에서 오직 이 페이지에서만 유효합니다.
High Detail 모드
-
Red 분석 도구 High Detail 모드
-
Green 분류 도구 High Detail 모드
-
Green 분류 도구 High Detail Quick 모드
Focused 모드
-
Red 분석 도구 Focused 지도 모드
-
Red 분석 도구 Focused 비지도 모드
-
Blue 읽기
-
Blue 위치
-
Green 분류 – Focused
High Detail 모드
High Detail 모드 도구들은 GPU 자원이 도구 단위로 점유됩니다:
-
1개 도구의 트레이닝(트레이닝할 도구의 모든 이미지)은 오직 1개의 GPU를 점유
-
1개 도구의 프로세싱(프로세싱할 도구의 모든 이미지)은 오직 1개의 GPU를 점유
이는 어떤 High Detail 모드 도구가 트레이닝 또는 프로세싱을 위해 GPU를 점유할 때, 이 GPU는 "잠김" 상태에 들어감을 의미합니다. 따라서 이 High Detail 모드 도구의 트레이닝 또는 프로세싱 작업을 모두 마치기 전까지는 이 GPU는 잠긴 상태이며, 다른 어떤 도구도 잠겨있는 이 GPU 자원을 활용할 수 없습니다.
만약 트레이닝 또는 프로세싱을 할 N개의 High Detail 모드 도구가 있고 1개 GPU가 있을 때, 이들 N개 High Detail 모드 도구들은 순차적으로 이 1개 GPU를 점유합니다(선입선출). 일단 어떤 도구가 프로세싱 또는 트레이닝을 위해 이 GPU를 점유하면 이 작업이 끝날때까지 다른 도구들은 큐(Queue)에서 대기합니다. 만약 이 상태에서 새로운 트레이닝 또는 프로세싱 작업을 실행하면, 이 작업은 큐의 마지막 위치에 추가됩니다.
High Detail 모드들로 이뤄진 도구 체인
High Detail 모드 도구 체인에서도 위 GPU 자원 배분 원리가 1가지 예외를 제외하고 동일하게 적용됩니다.이 예외는 부모 도구(업스트림 도구)가 항상 먼저 트레이닝되고 그 다음에 자식 도구(다운스트림 도구)가 트레이닝되는 것입니다. 자식 도구들 사이에서는 위 원리가 동일하게 적용됩니다.
예를 들어, 1개 부모 도구와 2개 자식 도구들이 있을 때, 이 도구 체인의 트레이닝은 순차적으로 진행됩니다. 부모 도구는 항상 먼저 트레이닝 됩니다.
High Detail 모드 도구 체인을 1개 GPU로 트레이닝할 때 자원 배분 예시
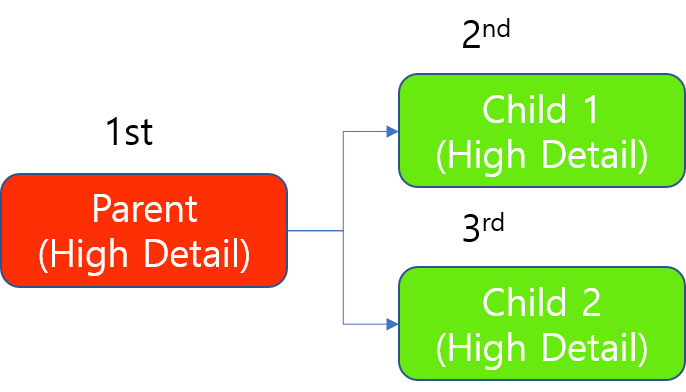
프로세싱 시에도 부모 도구는 항상 먼저 프로세스됩니다. 프로세싱 시에도 High Detail 도구는 "도구 단위"로 GPU를 점유하기 때문에, 1개 GPU가 있을 때 자식 도구는 한 번에 1개씩 순차적으로 프로세싱됩니다. 나머지 자식 도구는 먼저 시작된 프로세싱(먼저 GPU를 점유한 자식 도구의 모든 이미지에 대한 프로세싱)이 끝난 다음에 순차적으로 프로세싱을 시작합니다.
High Detail 모드 도구 체인을 1개 GPU로 프로세싱할 때 자원 배분 예시(트레이닝과 동일)
Focused 모드
Focused 모드 도구들은 GPU 자원이 트레이닝 시에는 도구 단위로, 프로세싱 시에는 이미지 단위로 점유됩니다:
-
1개 도구의 트레이닝(트레이닝할 도구의 모든 이미지)은 오직 1개의 GPU를 점유
-
1개 이미지의 프로세싱(프로세싱할 도구의 1개 이미지)은 오직 1개의 GPU를 점유
이는 어떤 Focused 모드 도구가 트레이닝을 위해 GPU를 점유할 때, 이 GPU는 "잠김" 상태에 들어감을 의미합니다. 따라서 이 Focused 모드 도구의 트레이닝 작업을 모두 마치기 전까지는 이 GPU는 잠긴 상태이며, 다른 어떤 도구도 잠겨있는 이 GPU 자원을 활용할 수 없습니다.
만약 트레이닝을 할 N개의 Focused 모드 도구가 있고 1개 GPU가 있을 때, 이들 N개 Focused 모드 도구들은 순차적으로 이 1개 GPU를 점유합니다(선입선출). 일단 어떤 도구가 트레이닝을 위해 이 GPU를 점유하면 이 작업이 끝날때까지 다른 도구들은 큐(Queue)에서 대기합니다. 만약 이 상태에서 새로운 트레이닝 작업을 실행하면, 이 작업은 큐의 마지막 위치에 추가됩니다.
하지만, 어떤 Focused 모드 도구가 1개 GPU를 프로세싱을 위해 점유할 때, 이 GPU는 이 도구의 1개 이미지에 대한 프로세싱이 끝날 때 까지만 점유됩니다. 이 도구의 1개 이미지에 대한 프로세싱이 끝난 직후 이 GPU는 다른 모든 도구(대부분 큐의 앞 쪽에서 대기하던 도구)에 의해서 점유될 수 있으며, 보통 1개 GPU에 대한 프로세싱 시간은 매우 짧습니다.
Focused 모드 도구들 역시 선입선출 큐를 사용하므로 N개의 Focused 모드 도구들이 있을 때 어떤 도구가 프로세싱을 위해 이 GPU를 점유하면, 다른 모든 도구들은 이 도구의 1개 이미지에 대한 프로세싱이 끝날 때까지 큐에서 대기합니다. 하지만 1개 이미지에 대한 프로세싱 시간은 보통 매우 짧으므로 N개의 Focused 모드 도구들은 이 GPU를 번갈아 가며 점유합니다.
-
만약 새로운 트레이닝 작업을 실행하면 이 작업은 선입선출 큐에 추가되고 차례가 오면 모든 이미지에 대한 트레이닝 작업이 끝날 때까지 GPU 자원을 점유합니다.
-
만약 새로운 프로세싱 작업을 실행하면 이 작업은 선입선출 큐에 추가되고 차례가 오면 1개 이미지에 대한 프로세싱 작업이 끝날 때까지 GPU 자원을 잠시 점유합니다. 프로세싱 작업이 끝나면 GPU 점유를 해제하고 다른 이미지의 프로세싱을 위해 이 GPU 또는 다른 GPU를 점유합니다. 이 과정은 도구에 속한 모든 이미지에 대한 프로세싱이 끝날 때까지 반복됩니다.
Focused 모드들로 이뤄진 도구 체인
Focused 모드 도구 체인에서도 위 GPU 자원 배분 원리가 1가지 예외를 제외하고 동일하게 적용됩니다.이 예외는 부모 도구(업스트림 도구)가 항상 먼저 트레이닝되고 그 다음에 자식 도구(다운스트림 도구)가 트레이닝되는 것입니다. 자식 도구들 사이에서는 위 원리가 동일하게 적용됩니다.
예를 들어, 1개 부모 도구와 2개 자식 도구들이 있을 때, 이 도구 체인의 트레이닝은 순차적으로 진행됩니다. 부모 도구는 항상 먼저 트레이닝 됩니다.
Focused 모드 도구 체인을 1개 GPU로 트레이닝할 때 자원 배분 예시
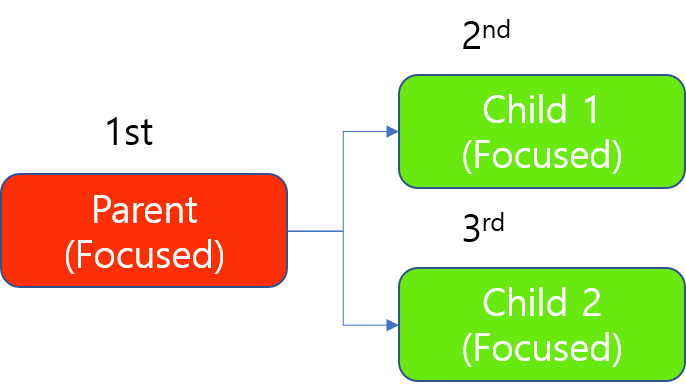
프로세싱 시에도 부모 도구는 항상 먼저 프로세스됩니다. 하지만 Focused 도구의 프로세싱은 GPU를 "이미지 단위"로 점유하므로 2개 자식 도구들은 1개 GPU에서도 동시에 프로세싱될 수 있습니다. 이 GPU가 2개 자식 도구 중 어느 하나의 이미지에 대한 프로세싱을 마치는 순간 이 GPU는 잠김 상태에서 해제되기 때문입니다.
Focused 모드 도구 체인을 1개 GPU로 트레이닝할 때 자원 배분 예시
(Focused 모드의 프로세싱은 도구의 모든 이미지가 아닌 도구의 1개 이미지를 프로세싱 완료할 때까지만 GPU를 점유함)
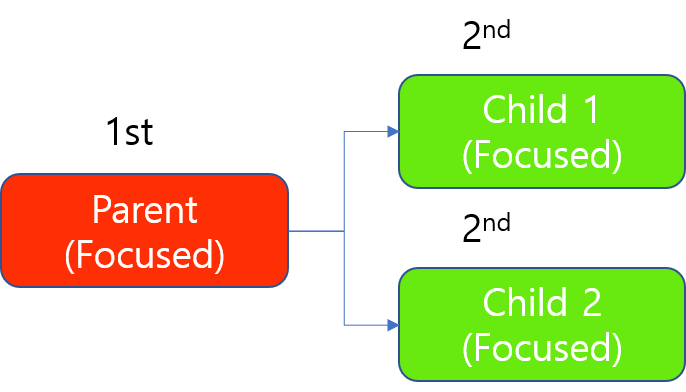
자원 배분 우선 순위
-
High Detail 모드 > Focused 모드
스트림에 High Detail 모드와 Focused 모드 도구가 함께 있을 때, High Detail 모드는 Focused 모드에 우선하여 프로세싱됩니다. 따라서 이 경우 High Detail 도구들은 GPU를 미리 점유합니다. 그리고 나서 Focused 모드 도구들이 High Detail 도구들이 점유하고 있지 않은 GPU들을 점유합니다.