Code128 Considerations
Code128 is unique among the symbologies supported by the Barcode tool in that it uses shift codes to switch between multiple character sets. For example, Code Set C uses values 0 through 99 to represent the 100 possible pairs of digits. An entirely numeric barcode might start with the Start C code, while an alphanumeric barcode might use the CODE C and CODE A codes to switch in and out the Code Set C. This use of shift codes means that the number of raw bytes in a barcode will likely be different than the number of characters in the decoded symbol.
Decoding a Code128 symbol shows an example of how the number of raw bytes in a Code128 symbol may differ from the number of characters in the decoded string.
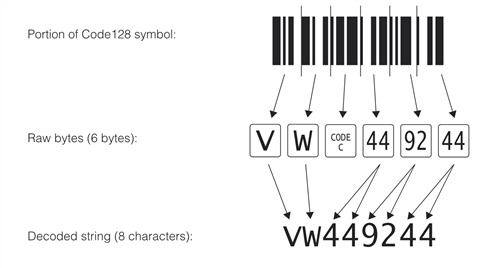
If you specify field codes for a Code128 symbol, you should match the field codes with the decoded string as you would for other barcodes. It does not matter where the control characters are placed in the barcode. However, best results are obtained by not specifying fielding for Code128. This is true for two reasons:
- Code128 is used only in label applications where there is little or no confusion in the barcode region. Hence, the Barcode tool can easily determine the length of the string and the encoded characters.
- In Code128 symbology, a single string can be split across multiple barcodes by using a certain control character. In such cases, specifying fielding to indicate the length of the encoded string can be meaningless.